Flume definition
![]()
![]() Apache Flume is a distributed service that reliably and efficiently moves large amounts of data, especially logs. Ideal for online analytics applications in Hadoop environments.
Apache Flume is a distributed service that reliably and efficiently moves large amounts of data, especially logs. Ideal for online analytics applications in Hadoop environments.
Flume has a simple and flexible architecture based on streaming data, which allows to build multiple flows streams through which events travel through different agents until they reach the final destination.
Features
- Perfectly integrated into the Hadoop ecosystem, an example of this is the integration of Sink HDFS or Hbase in Keberos.
- Specialized in log data.
- It allows the collection and aggregation of logs in a simple way.
- Designed for simple events, not for complex events.
- Robust and fault-tolerant, with configurable reliability mechanisms and error and recovery.
- It allows the reading and writing of a multitude of data sources.
- Simplifies filtering and data transformation thanks to interceptors.
- Difficulty scaling horizontally, adding consumers implies changing the pipeline’s topology and adding a new destination.
- It supports ephemeral memory-based channels and durable, file-based channels, so it doesn’t work efficiently for long-term messages since it has to be retrieved from the agent.
- The file-based channels do not replicate data, so they are subject to disk errors, to solve it are usually replicated with root or SAN.
Architecture
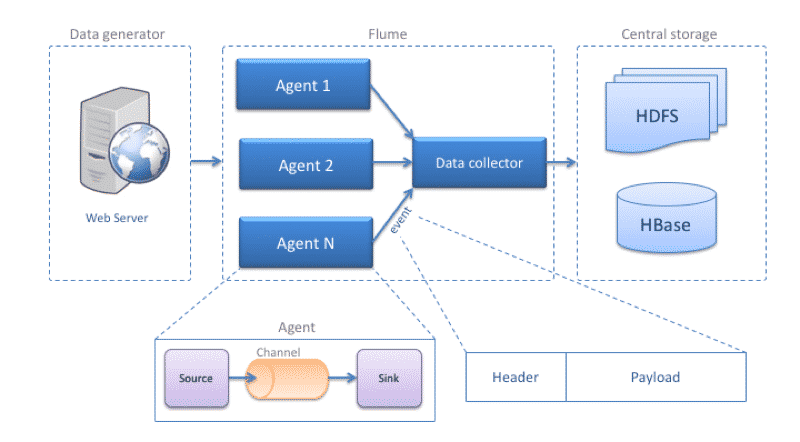
Apache Flume architecture
- Event: Represents the data unit in flume, counts for a byte load, and an optional header.
- Data flow: Describes the movement of events from the source to the destination, it should be noted that an event can go through agents that in a chained way before reaching its destination.
- Client — Interface implementation that operates at the point of origin of events and delivers them to agents. Customers typically operate in the application process space they are consuming data from. Log4j Flume Appender is a client example.
- Agent: It is an independent process that takes care of receiving, saving and sending events, consists of:
- Source: Implementation of an interface that can consume events that are sent to you with a specific mechanism and put them in the channel. Avro is an example of an interface.
- Channel: Transient event store. Events are delivered to the channel through the sources that operate on the agent. An event remains on a channel remains in the channel until a receiver removes it for later transport. JDBC is a channel example that uses a file system-supported embedded database to conserve events until they are deleted by a receiver.
- Sink: Implementation of an interface that allows to consume events from one channel and transmit them to the next agent or to the final destination. Flume HDFS is an example of Sink.
Source: Official website




0 Comments