Para poder comprender como clasificar sonidos utilizando redes neuronales convolucionales se recomienda primero entender el caso básico de redes neuronales multicapa.
Extracción de caracteristicas refinada
En la etapa de extracción de características anterior, los vectores MFCC variarían en tamaño para los diferentes archivos de audio (dependiendo de la duración de las muestras).
Las CNN requieren un tamaño fijo para todas las entradas, por ello vremos cual es el máximo y rellenaremos a cero los vectores de salida inferiores.
import numpy as np
max_pad_len = 174
def extract_features(file_name):
try:
audio, sample_rate = librosa.load(file_name, res_type='kaiser_fast')
mfccs = librosa.feature.mfcc(y=audio, sr=sample_rate, n_mfcc=40)
pad_width = max_pad_len - mfccs.shape[1]
mfccs = np.pad(mfccs, pad_width=((0, 0), (0, pad_width)), mode='constant')
except Exception as e:
print("Error encountered while parsing file: ", file_name)
return None
return mfccs# Load various imports
import pandas as pd
import os
import librosa
features = []
# Iterate through each sound file and extract the features
for index, row in metadata.iterrows():
file_name = os.path.join(os.path.abspath(fulldatasetpath),'fold'+str(row["fold"])+'/',str(row["slice_file_name"]))
class_label = row["classID"]
data = extract_features(file_name)
features.append([data, class_label])
# Convert into a Panda dataframe
featuresdf = pd.DataFrame(features, columns=['feature','class_label'])
print('Finished feature extraction from ', len(featuresdf), ' files') Convertir los datos y etiquetas
Para transformar los datos categóricos a numéricos, usaremos LabelEncoder y así conseguiremos que el modelo sea capaz de entenderlos.
from sklearn.preprocessing import LabelEncoder
from keras.utils import to_categorical
# Convert features and corresponding classification labels into numpy arrays
X = np.array(featuresdf.feature.tolist())
y = np.array(featuresdf.class_label.tolist())
# Encode the classification labels
le = LabelEncoder()
yy = to_categorical(le.fit_transform(y)) Dividir los datos en entrenamiento y test¶
Dividimos el conjunto de datos en dos bloques (80% y 20%) y de ellos sacamos valores de X y de Y.
# split the dataset
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, yy, test_size=0.2, random_state = 42)Construir el modelo
Construiremos un modelo de red neuronal, concretamente utilizaremos una red neuronal convolucional.
Las redes neuronales convolucionales funcionan muy bien para la clasificación de imágenes, debido a la extracción de características y partes a clasificar.
Viendo el comportamiento de MFCC, observamos que se puede extrapolar al comportamiento que tienen estas redes en imágenes.
Para su implementación, utilizaremos un modelo secuencial, comenzando con una arquitectura de modelo simple, que consta de cuatro capas de convolución Conv2D con sus capas de poolling, siendo nuestra capa de salida final una capa densa.
Las capas de convolución están diseñadas para la detección de características. Funciona deslizando una ventana de filtro filter sobre la entrada y realizando una multiplicación de matriz y almacenando el resultado en un mapa de características. Esta operación se conoce como convolución.
El parámetro de filtro especifica el número de nodos en cada capa. Cada capa aumentará de tamaño de 16, 32, 64 a 128, mientras que el parámetro kernel_size especifica el tamaño de la ventana del kernel, que en este caso es 2, lo que da como resultado una matriz de filtro 2×2.
La primera capa recibirá la forma de entrada de (40, 174, 1) donde 40 es el número de MFCC, 174 es el número de cuadros que tienen en cuenta el relleno y el 1 significa que el audio es mono.
La función de activación que utilizaremos para nuestras capas convolucionales es ReLU.
También destacar que aplicaremos un Dropout del 20%. Esto excluirá al azar los nodos de cada ciclo de actualización, lo que a su vez da como resultado una red que es capaz de responder mejor a la generalización y es menos probable que se produzca sobreajuste en los datos de entrenamiento.
Cada capa convolucional tiene una capa de agrupación asociada de tipo MaxPooling2D con la capa convolucional final que tiene un tipo GlobalAveragePooling2D. La capa de agrupación reduce la dimensionalidad del modelo (al reducir los parámetros y los requisitos de cálculo subsiguientes), lo que sirve para acortar el tiempo de entrenamiento y reducir el sobreajuste. El tipo de agrupación máxima toma el tamaño máximo para cada ventana y el tipo de agrupación promedio global toma el promedio que es adecuado para alimentar nuestra capa de salida densa.
Finalmente la capa de salida tendrá 10 nodos, que coinciden con el número de clasificaciones posibles. La activación es para nuestra capa de salida la función softmax. Softmax hace que la salida sume 1, por lo que la salida puede interpretarse como probabilidades. El modelo hará su predicción según la opción que tenga la mayor probabilidad.
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, Conv2D, MaxPooling2D, GlobalAveragePooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
from sklearn import metrics
num_rows = 40
num_columns = 174
num_channels = 1
x_train = x_train.reshape(x_train.shape[0], num_rows, num_columns, num_channels)
x_test = x_test.reshape(x_test.shape[0], num_rows, num_columns, num_channels)
num_labels = yy.shape[1]
filter_size = 2
# Construct model
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=2, input_shape=(num_rows, num_columns, num_channels), activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.2))
model.add(Conv2D(filters=32, kernel_size=2, activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.2))
model.add(Conv2D(filters=64, kernel_size=2, activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.2))
model.add(Conv2D(filters=128, kernel_size=2, activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.2))
model.add(GlobalAveragePooling2D())
model.add(Dense(num_labels, activation='softmax')) Compilar el modelo
Para compilar nuestro modelo, utilizaremos los siguientes tres parámetros:
- Función de pérdida: utilizaremos
categorical_crossentropy. Esta es la opción más común para la clasificación. Una puntuación más baja indica que el modelo está funcionando mejor. - Métricas: utilizaremos la métrica de
accuracyque nos permitirá ver la precisión en los datos de validación cuando entrenemos el modelo. - Optimizador: aquí usaremos
adam, que generalmente es un buen optimizador para muchos casos de uso.
# Compile the model
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
# Display model architecture summary
model.summary()
# Calculate pre-training accuracy
score = model.evaluate(x_test, y_test, verbose=1)
accuracy = 100*score[1]
print("Pre-training accuracy: %.4f%%" % accuracy)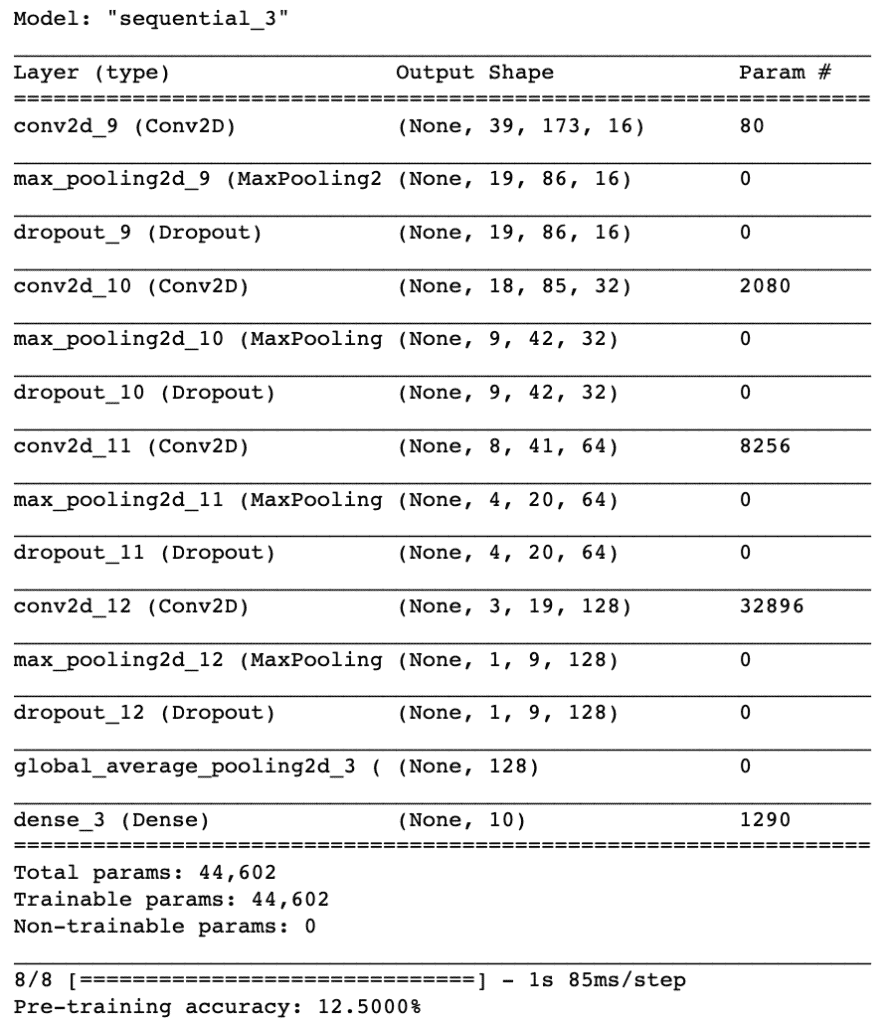
Entrenar el modelo
Se empieza probando con un número de épocas bajo y se prueba hasta ver donde alcanza un valor asintótico en el que por más que subamos las épocas no conseguimos que el modelo mejore significativamente.
Por otro lado, el tamaño del lote debe ser suficientemente bajo, ya que tener un tamaño de lote grande puede reducir la capacidad de generalización del modelo.
from keras.callbacks import ModelCheckpoint
from datetime import datetime
#num_epochs = 12
#num_batch_size = 128
num_epochs = 72
num_batch_size = 256
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.basic_cnn.hdf5',
verbose=1, save_best_only=True)
start = datetime.now()
model.fit(x_train, y_train, batch_size=num_batch_size, epochs=num_epochs, validation_data=(x_test, y_test), callbacks=[checkpointer], verbose=1)
duration = datetime.now() - start
print("Training completed in time: ", duration)Evaluar el modelo
Finalmente, para determinar la precisión del modelo generado, llamamos a la función evaluate y le pasamos los datos de test que hemos definido previamente.
# Evaluating the model on the testing set
score = model.evaluate(x_test, y_test, verbose=0)
print("Testing Accuracy: ", score[1])Si analizamos el valor obtenido con todo el conjunto de test, teniendo en cuenta el conjunto de datos completo, vemos que la precisión ha mejorado en torno al 6%.




0 comentarios