Definición de Flink
![]()
![]() Apache Flink es un motor nativo de procesamiento de flujos de datos de baja latencia, que proporciona capacidades de distribución de datos comunicación y tolerancia a fallos.
Apache Flink es un motor nativo de procesamiento de flujos de datos de baja latencia, que proporciona capacidades de distribución de datos comunicación y tolerancia a fallos.
Flink fue desarrollado en Java y Scala por la Universidad Técnica de Berlin y actualmente es la start-up Data Artisans la que se encarga de dar soporte y realizar mejoras.
Las aplicaciones que obtienen mejores rendimientos de Flink son:
- Sistemas distribuidos que den respuesta rápidamente a preguntas computacionalmente complejas de machine learning, estadística, …
- Procesos de limpieza y pre-filtrado sobre grandes cantidades de datos.
- Detección de anomalías.
- Sistemas de monitorización de alertas en tiempo real.
- Proyectos de IOT.
Características
- Proporciona API de programación para Java, Scala, Python, R, SQL
- Proporciona librerías para CEP (Procesamiento complejo de eventos), Machine Learning y Grafos
- Muy Baja latencia, gracias al motor de streaming nativo puede procesar batch de milisegundos.
- Tolerancia a fallos a través de un sistema de snapshots distribuidos.
- Soporta eventos desordenados gracias a Watermarks
- Sistema de gestión de ventanas flexible que permite definir 3 tipos de ventanas:
- definir el tamaño.
- definir el intervalo por tiempo.
- definir el intervalo por número de eventos.
- Además el sistema de gestión de ventanas permite definir opciones avanzadas como:
- triggers que permiten lanzar la ejecuciones de ventana al cumplirse condiciones específicas.
- evictors que permiten eliminar elementos de la ventana bajo condiciones específicas
- Alto rendimiento (throughput), ya que es capaz de procesar millones de eventos por segundo.
- Consistencia, ya que se obtienen resultados correctos incluso en caso de errores.
Componentes
La base de Flink es el nucleo «core» y es donde se encuentran todas las APIs y librerías de utilidades
Principales APIs:
- DataSet API es el entorno de ejecución en el que las transformaciones se ejecutan sobre conjuntos de datos tomados de fuentes estáticas, como por ejemplo bases de datos locales o ficheros.
- DataStream API es el entorno de ejecución en el que las transformaciones se ejecutan sobre conjuntos de datos tomados de fuentes dinámicas, como por ejemplo sockets o colas de mensajes.
Librerías:
- Optimizador de programas.
- Constructor de streams.
- FlinkML es la librería machine learning.
- Gelly librería para la creación y análisis de grafos.
- Table API permiten utilizar expresiones con una sintaxis SQL.
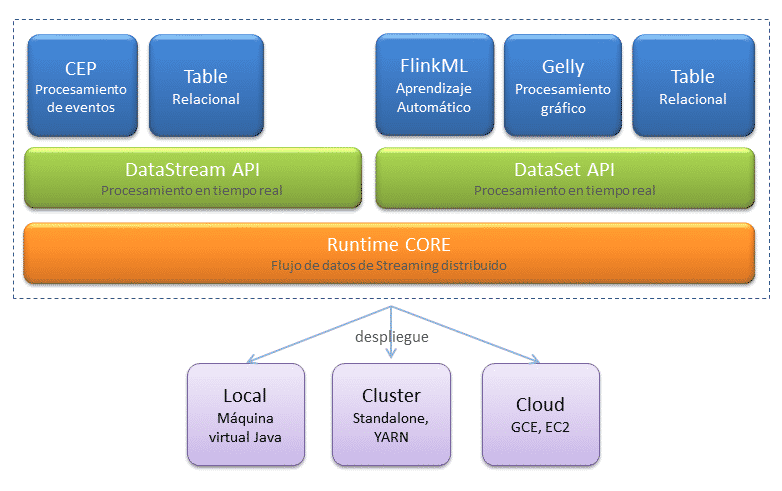
Componentes de Flink
Principales componentes para el trabajo con Flink:
- Streams son los conjuntos de datos inmutables e ilimitados que fluyen a través del sistema.
- Operators son funciones que operan en flujos de datos para producir otros streams.
- Sources son el punto de entrada para los streams que ingresan al sistema
- Sinks son el lugar donde fluyen los streams del sistema, pueden representar una base de datos o un conector a otro sistema.
Arquitectura
Se basa en una arquitectura cliente servidor en la que el sistema Flink levanta un JobManager, que hace de coordinador de todo el sistema, y uno o más TaskManager, encargados de ejecutar partes del código en paralelo.
Por otro lado cabe destacar que es el Optimizer/Graph Builder el que se encarga de transformar el código a un DataFlow, que sea ejecutable de forma paralela por los TaskManager.
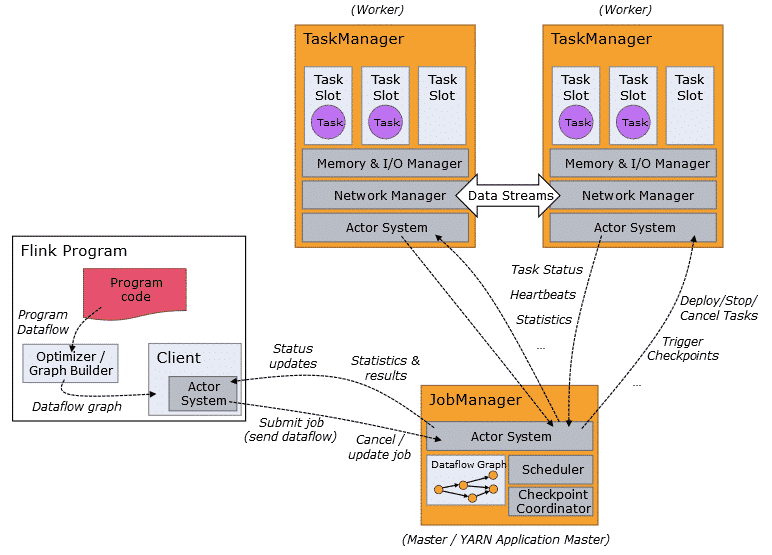 Fuente: Web Oficial
Fuente: Web Oficial




0 comentarios