Los almacenes de datos en columnas, son un tipo de base de datos relacional.
En esencia consiste en partir la tabla lógica en tantos fragmentos como columnas tenga la tabla lógica. Cada elemento de la tabla inicial estará formado por los datos colocados la posición i-esima (indicadores de filas implícitos o implicit rowid), es decir que para reconstruir una fila basta con acudir a la posición n de cada uno de los fragmentos.
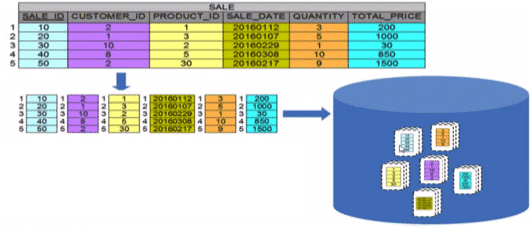
Fuente: Universidad Oberta de Cataluña
Los almacenes de columnas mantienen los datos ordenados físicamente en disco en función del valor que toma una columna o grupo de columnas, para optimizar su rendimiento se pueden guardar duplicados ordenados por diferentes criterios, esto se conoce como proyecciones.
Los almacenes de datos en columnas se caracterizan por:
- Los datos de cada columna se almacenan en un fichero separado.
- Los datos de las columnas se almacenan de forma ordenada, esto hace que los datos parecidos se encuentren cercanos, este nivel de entropia bajo facilita la compresión de datos.
- Cada fichero únicamente almacena datos de una columna.
- Se minimiza la necesidad de guardar información de control en cada página de datos.
- No se guardan de forma explícita datos que permitan reconstruir las filas (clave primaria).
Se diferencia de las base de datos relacionales en filas clásicas (Postgresql, Oracle, MySql) en:
- La información se almacena directamente en memoria
- La información se almacena por columnas en vez de por filas
- Facilita la ejecución de ciertos tipos de consultas SELECT ( idónea para entornos de naturaleza analítica, sistemas CRM, búsqueda de catálogos).
- Facilita las agrupaciones y cálculos agregados, sobre pocas columnas pero con un volumen importante de datos.
- Facilita la adicción y eliminación de columnas en las tablas.
- Problemas con las operaciones de cambios (INSERT, DELETE y UPDATE)
Ejemplos de base de datos por columna; Vertica (comercializado por HP), Actian Vector, MonetDB (open source), Infobringht, SAP Sybase IQ o Amazon Redshift.
Aunque debido a su potencial las bases de datos clásicas de filas (Oracle, Posgresql, SQL Server,…) lo han implementado a través de extensiones.




0 comentarios