Definición de Kafka
Apache Kafka es un sistema de intermediación de mensajes basado en el modelo publicador/suscriptor.
Se considera un sistema persistente, escalable, replicado y tolerante a fallos. A estas características se añade la velocidad de lecturas y escrituras que lo convierten en una herramienta excelente para comunicaciones en tiempo real (streaming).
Proporciona multitud de conectores que le hacen conectarse a casi cualquier fuente de datos, como conectores para ActiveMQ, IBM MQ, JDBC, JMS, Replicator, …
También proporciona multitud de conectores que le hacen almacenar los datos en cualquier sitio, como conectores para HDFS, Amazon S3, Elasticsearch, JDBC, …
Características
- Desarrollado en Scala.
- Dispone de conectores para la integración con JMS, sistema de archivos, Hadoop(HDFS), HBase, FTP, JDBC, MongoDB, assandra, API REST,…
- Permite la implementación de productores/consumidores en diferentes lenguajes: Java, Scala, Python, Ruby, C++,…
- Utiliza un protocolo propio agnóstico que va sobre http.
- Utiliza Apache Zookeeper para almacenar el estado de los nodos, que mantiene un conjunto de particiones de cada topic.
- Permite ingestar grandes volumenes de datos, entrono a 100k eventos/seg.
- Buen rendimiento ente latencias bajas.
- Permite escalamiento horizontal.
- Diferentes grupos de consumidores pueden consumir mensajes a diferente ritmo.
- Actúa de amortiguador entre productores y consumidores, ideal para absorber picos de carga.
- Software de código abierto que se distribuye bajo licencia Apache 2.0
Arquitectura
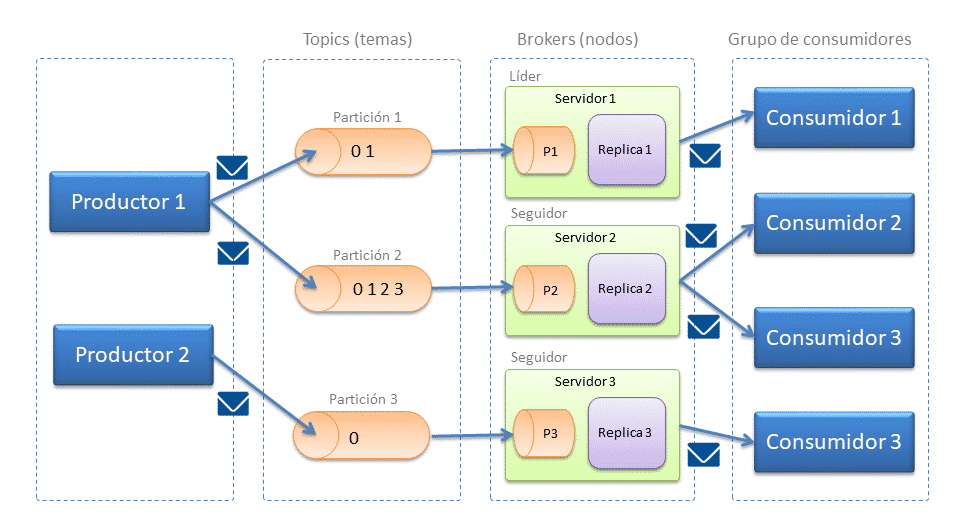
Arquitectura Kafka
Topic (tema): Categorías en las que clasificar los mensajes enviados a Kafka.
Producer (productor) Clientes conectados responsables de publicar los mensajes. Estos mensajes son publicados sobre uno o varios topics.
Consumer (consumidor) Clientes conectados suscritos a uno o varios topics encargados de consumir los mensajes.
Broker (nodos): Nodos que forman el cluster.
Offset: es el indicador que indica a cada consumidor el último elemento que ha leído. Esto hace que si se cae el sistema no se pierdan los datos.
¿Cómo funciona?
Apache Kafka divide cada topics (mensaje) en particiones. Cada partición es una secuencia ordenada de mensajes y cada partición es consumida por un único consumidor. Aunque se consuma la partición no se subtrae por el consumidor.
A cada topic se le puede definir un número de particiones, en función del numero de servidores y de conexiones que vayamos a tener. Esto aumenta considerablemente la disponibilidad.
Cada topic tiene un offset para que cada consumidor indique que mensaje quiere que se le devuelva. A mayor número de particiones más tardará el productor (escribe mensajes) en guardar el mensaje, pero tardará menos el consumidor (lee mensajes) en recuperarlo. La idea está pensada para procesamiento en paralelo.
Cada mensaje publicado en un topic se entrega a una instancia de consumidor dentro de cada grupo de consumidores suscriptores.
Apache Kafka se distribuye junto con Zookeeper para su instalación. Cuando solicitas un mensaje no te conectas a Kafka sino a Zookeeper. Zookeeper es una forma muy cómoda de escalar horizontalmente.
Zookeeper está compuesto por brokers que actúan como líder de una o mas particiones, el líder es activo y el seguidor pasivo.




Buenas! Necesito un profesor de KAFKA para impartir un curso de 16 horas en Madrid en Octubre/2019 en un gran Integrador. Soy Fátima Escrivá de Romaní, Key Account Manager de DUONET ¿me podéis ayudar?