Yarn definition
Yarn (Yet Another Resource negotiator) is a data operating system and distributed Resource Manager, also known as Hadoop 2 as it is the evolution of Hadoop Map-Reduce.
The most significant changes of Hadoop 2 over Hadoop 1 is that the thread technology is included, this technology provides an effective allocation of resources, for it runs two demons:
Resource Manager: responsible for managing the resources on their multiple nodes.
Application Master: responsible for negotiating resources with the resource manager on the one hand and with the node manager to run and monitor for another. There will be a master application for each “job” sent to the cluster.
Architecture
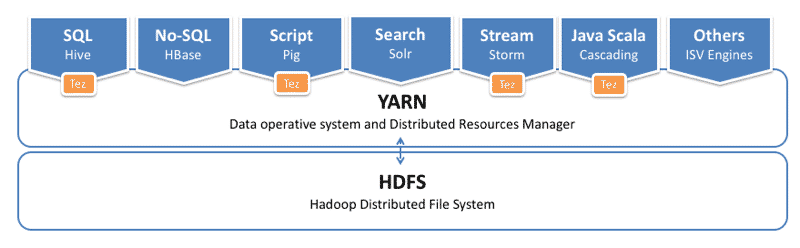
Hadoop YARN achitecture
View Yarn Processes
The service of Yarn in cloudy or Hortoworks is usually configured in Port 8088
http://localhost:8088 or http://127.0.0.1:8088
Commands
Commands used in the Hortonworks shell:
Restore Service:
sudo service Ambari-server restart
View the Process list
yarn application -list -appStates ALL
Note You can specify the processes by the state by changing ALL by: NEW, NEW_SAVING, submitted, accepted, RUNNING, finished, failed, killed.
Kill applications ripped off
yarn application -kill
View Logs Concrete Application
yarn logs -applicationId <id-aplicación>
Source: Official website
Source: Commands




0 Comments