Flink definition
![]()
![]() Apache Flink is a native low-latency data flow processing engine that provides communication and fault tolerance data distribution capabilities.
Apache Flink is a native low-latency data flow processing engine that provides communication and fault tolerance data distribution capabilities.
Flink was developed in Java and Scala by the Technical University of Berlin and is currently the start-up Data artisans which is responsible for supporting and making improvements.
The applications that obtain the best performance from Flink are:
- Distributed systems that respond quickly to computationally complex questions of machine learning, statistics,…
- Cleaning and pre-filtering processes on large amounts of data.
- Anomaly detection.
- Real-time alert monitoring systems.
- IOT projects.
Features
- Provides programming API for Java, Scala, Python, R, SQL
- Provides libraries for CEP (complex event processing), Machine Learning and graphs
- Very low latency, thanks to the native streaming engine you can process batch of milliseconds.
- Fault tolerance through a distributed snapshot system.
- Supports messy events thanks to watermarks
- Flexible window management system that allows you to define 3 types of Windows:
- Define the size.
- Set the time interval.
- Set the interval by number of events.
- In addition, the window management system allows you to define advanced options such as:
- Triggers that allow window executions to be released when specific conditions are fulfilled.
- Evictors that allow you to remove items from the window under specific conditions
- High throughput, because it is capable of processing millions of events per second.
- Consistency, because correct results are obtained even in case of errors.
Components
The base of Flink is the nucleus core and is where all the APIs and utilities libraries are located
Main APIs:
- DataSet API is the runtime environment in which transformations are executed over data sets taken from static sources, such as local databases or files.
- DataStream API is the runtime environment in which transformations are executed over data sets taken from dynamic sources, such as sockets or message queues.
Libraries:
- Program Optimizer.
- Stream Builder.
- FlinkML is the machine learning Library.
- Gelly Library for the creation and analysis of graphs.
- Table API allows you to use expressions with an SQL syntax.
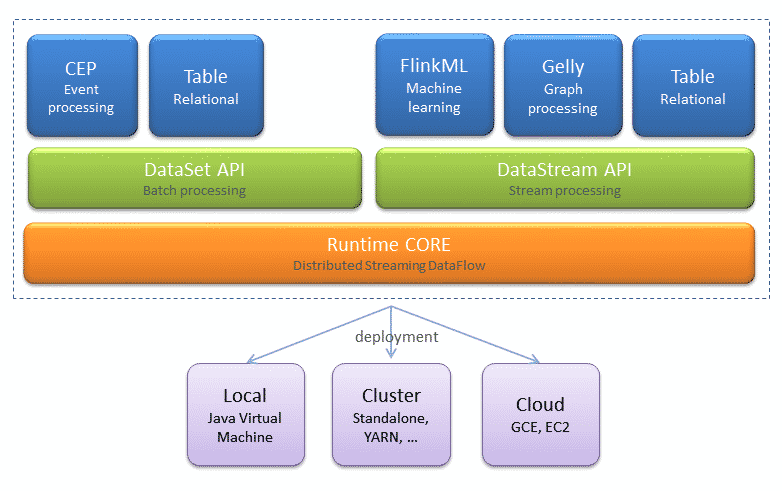
Flink componets
Main components for working with Flink:
- Streams are the unchangeable and unlimited data sets that flow through the system.
- Operators are functions that operate in data streams to produce other streams.
- Sources are the entry point for streams entering the system
- Sinks are the place where streams flow from the system, can represent a database or a connector to another system.
Architecture
It is based on a client server architecture in which the Flink system raises a JobManager, which makes the system-wide coordinator, and one or more TaskManager, responsible for executing parts of the code in parallel.
On the other hand it is noteworthy that it is the Optimizer/Graph Builder that is responsible for transforming the code to a DataFlow, which is executable parallel by the TaskManager.
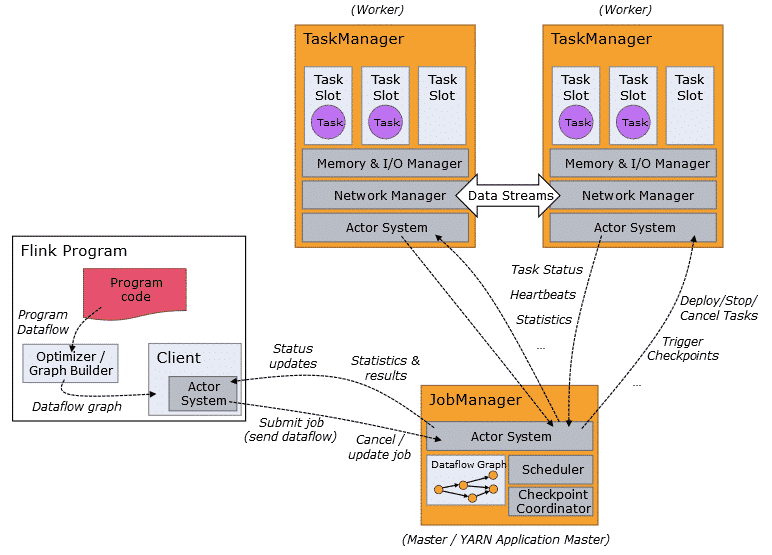 Source: Official website
Source: Official website




0 Comments