Definition of Nifi
A![]()
![]() pache NiFi is an integrated real-time data processing and logistics platform to automate data movement between different systems quickly, easily and securely.
pache NiFi is an integrated real-time data processing and logistics platform to automate data movement between different systems quickly, easily and securely.
Apache Hifi is an ETL tool that is responsible for loading data from different sources, passes it through a process flow for treatment, and dumps them into another source.
It is characterized by having a web interface, very powerful and intuitive that allows to design and visually configure the flow of data as well as to operate on the process (start and stop) and monitor the state in search of possible errors that are occurring.
Apache NiFi is based on “Niagara files”. It was developed and released by the NSA that used it since 2010.
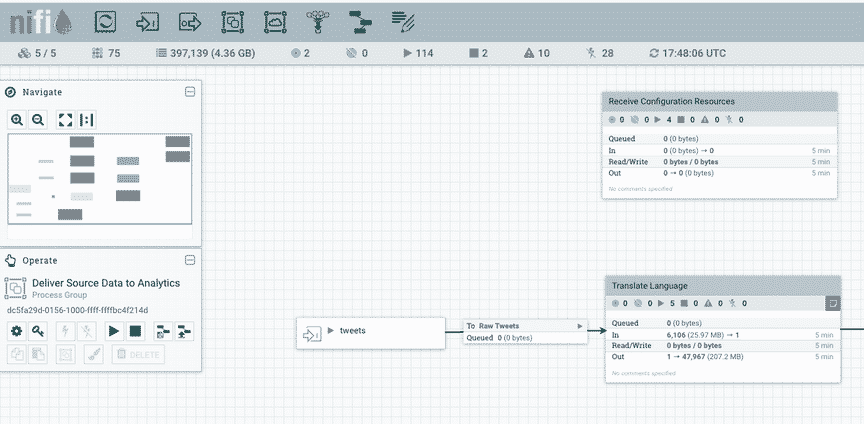
Nifi Application Example
Features
- Ingesting information does not affect the service performance of source or destination.
- Loading and recording data with a wide variety of technologies: HDFS, ElasticSearch, FTP, SQL databases, MongoDB,…
- Transformation between numerous data formats such as: JSON, XML, Avro, CSV,…
- Allows delegation of functionalities to other processing systems, such as:
- Apache Karfa: Bidirectional communication with a third party, by using queues.
- Apache Flume: Transparent execution of processes.
- Parallel execution using Apache ZooKeeper, which allows running multiple instances of Nifi (or MiNifi derivative project that provides a run-time with low requirements
- Independence of data sources, because it supports scattered and distributed sources of different formats, schemas, protocols, speeds and sizes, machines, geographical locations,…
- Provides a graphical interface that greatly facilitates treatment.
- Allows real-time data tracking.
- Flexibility to dynamically adjust to fluctuating network connectivity that could affect communications
Architecture

Architecture Apache Nifi
Web server: The purpose of the Web server is to host HTTP-based and API control.
Flow controller: The flow controller is the brain of the operation. Provides threads for extensions to run and manages planning when they will receive resources to run.
Extensions: There are several types of extensions but all extensions operate/run within the Java Virtual machine.
FlowFile repository: The file flow repository tracks the status of what you know about a flow file that is currently active in the stream. The repository implementation is pluggable. The default approach is a persistent advance-write record that lives on a specified disk partition.
Content repository: The content repository is where the actual content bytes of a particular FlowFile are found. The repository implementation is pluggable. The default approach is a fairly simple mechanism, which stores data blocks in the filesystem. You can specify more than one file-system storage location for different physical partitions in order to reduce to a single volume.
Provenance repository: The backgrounds repository is where all source event data are stored. Repository construction is connectable to the default implementation that includes one or more physical disk volumes. Within each location, the event data is indexed to be searchable.
Source: Official website




0 Comments