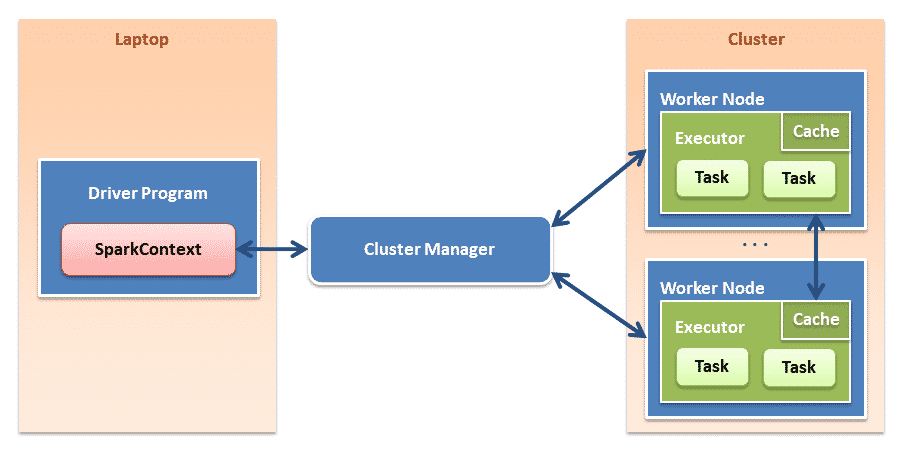
Arquitectura Spark
Spark context
SparkContext es el contexto básico de Spark, desde donde se crean el resto de variables.
En la shell de Spark viene directamente instancia en la variable «sc», aunque en otros entornos hay que instanciarlo explícitamente.
Problema que solo se puede instancias una sola vez por JVM.
La configuración de la estancia se puede definir mediante SparkConf.
RDD Resilient Distributed Datasets
Resilient Distributed Datasets “ o conjuntos distribuidos y flexibles de datos son grupos de datos de solo lectura generados tras realizar acciones en los datos originales.
Permiten cargar gran cantidad de datos en memoria y dividirse para ser tratados de forma paralela, con esto se consigue realizar operaciones en grandes cantidades de datos de forma rápida y tolerante a fallos.
Tipos de RDDs según su origen:
- Colecciones paralelizadas basadas en colecciones de Scala.
- Datasets de Hadoop creados a partir de ficheros almacenados en HDFS.
Tipos de operaciones sobre un RDD, según el resultado final:
- Transformaciones: crean nuevos conjuntos de datos. Estas a su vez se dividen según sus dependencias en:
- Narrow: las transformaciones están ubicadas cada una en la partición que le corresponde.
- filter()
- sample()
- map()
- fatMap()
- Wide: las transformaciones necesitan mezclar datos de diferentes particiones
- groupByKey()
- reduceByKey()
- Narrow: las transformaciones están ubicadas cada una en la partición que le corresponde.
- Acciones: devuelven un valor al driver del clúster después de llevar a cabo una computación sobre el conjunto de datos.
- reduce()
- collect()
- count()
- first()
- take()
Cluster Manager
Cluster Manager o gestor de cluster se encarga de asignar recursos en el sistema.
Spark soporta tres tipos de gestores de clusters:
- Standalone: Viene incluido con Spark, es un gestor muy sencillo.
- Apache Mesos: Gestor más avanzado, que puede ejecutar Hadoop, MapReduce y aplicaciones de servicio.
- Hadoop YARN: Gestor de recursos en Hadoop 2.
Executors
Executos son los encargados de ejecutar tareas (task) en los nodos del cluster.




0 comentarios