Clasificación de redes neuronales según la topología de red
Red neuronal Monocapa – Perceptrón simple
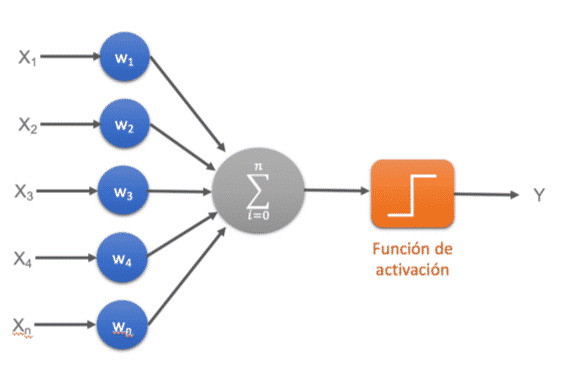
La red neuronal monocapa se corresponde con la red neuronal más simple, está compuesta por una capa de neuronas que proyectan las entradas a una capa de neuronas de salida donde se realizan los diferentes cálculos.
Red neuronal Multicapa – Perceptrón multicapa
La red neuronal multicapa es una generalización de la red neuronal monocapa, la diferencia reside en que mientras la red neuronal monocapa está compuesta por una capa de neuronas de entrada y una capa de neuronas de salida, esta dispone de un conjunto de capas intermedias (capas ocultas) entre la capa de entrada y la de salida.
Dependiendo del número de conexiones que presente la red esta puede estar total o parcialmente conectada.
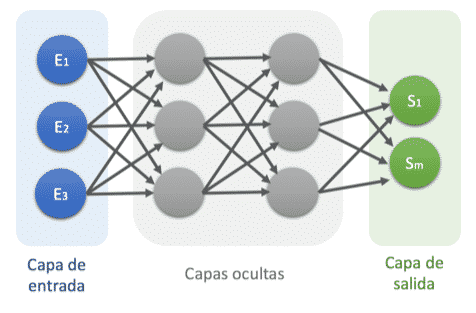
Perceptrón multicapa
Red neuronal Convolucional (CNN)
La principal diferencia de la red neuronal convolucional con el perceptrón multicapa viene en que cada neurona no se une con todas y cada una de las capas siguientes sino que solo con un subgrupo de ellas (se especializa), con esto se consigue reducir el número de neuronas necesarias y la complejidad computacional necesaria para su ejecución.
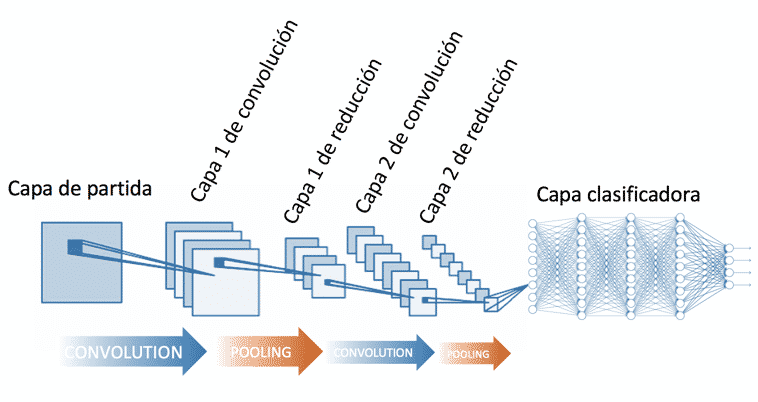
Red neuronal convolucional
Red neuronal recurrente (RNN)
Las redes neuronales recurrentes no tienen una estructura de capas, sino que permiten conexiones arbitrarias entre las neuronas, incluso pudiendo crear ciclos, con esto se consigue crear la temporalidad, permitiendo que la red tenga memoria.
Los datos introducidos en el momento t en la entrada, son transformados y van circulando por la red incluso en los instantes de tiempo siguientes t + 1, t + 2, …
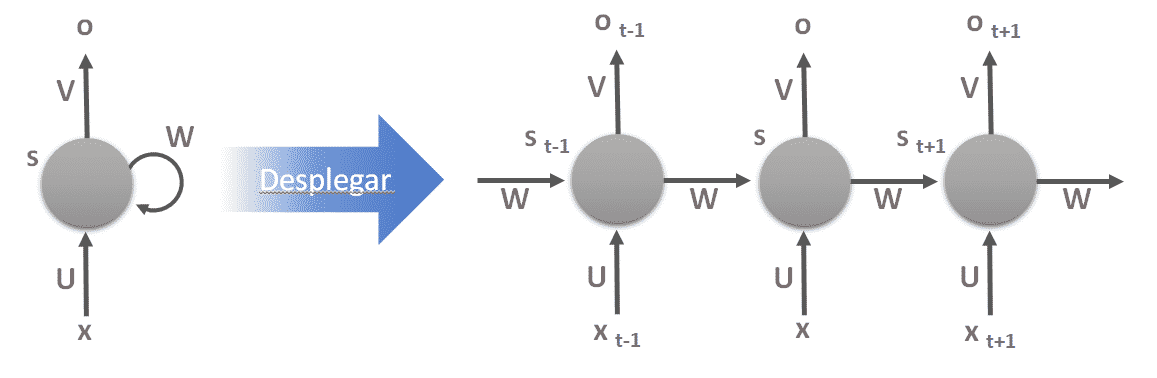
Red Neuronal Recurrente
Redes de base radial (RBF)
Las redes de base radial calculan la salida de la función en función de la distancia a un punto denominado centro. La salida es una combinación lineal de las funciones de activación radiales utilizadas por las neuronas individuales.
Las redes de base radial tienen la ventaja de que no presentan mínimos locales donde la retropropagación pueda quedarse bloqueada.
Redes de base radial
Clasificación de redes según el método de aprendizaje
Aprendizaje supervisado
Aprendizaje por corrección de error.
- Perceptrón
- Delta o Mínimo error cuadrado (LMS Error: Least Mean Squared)
- Backpropagation o Programación hacia atrás (LMS multicapa)
Aprendizaje estocástico
Aprendizaje no supervisado o autosupervisado
Se caracteriza porque no requieren influencia externa para ajustar los pesos.
Aprendizaje hebbiano
Permite medir la familiaridad o extraer las características de los datos de entrada.




Hola buenas tardes, voy a evaluar la comprensión lectora de los niños con redes neuronales artificiales.
Que metodología, modelo de RNA y lenguaje de programación me recomiendas.
agradezco su aporte.
El adecuado seria el algoritmo de enjambre usando c++
Hola buenas noches, voy a evaluar aptitudes y actitudes de estudiantes universitarios para ingenieria en sistemas con redes neuronales artificiales.
Que metodología, modelo de RNA y lenguaje de programación me recomiendas.
agradezco su aporte.
Buenas te recomiendo que utilices metodologías ágiles de desarrollo, programes en Python o R. En cuanto a los modelos prueba y compara resultados para quedarte con el que mejor se ajuste.
Hola buenas tardes, estoy comparan dos metdoso automáticos de redes neuronales artificiales en la prediccion de precios vivienda, ya realice uno con redes neuronales profundas pero me falta uno y no se con cual, tenia pensado con recurrentes pero no se, cual me recomendarías
Hola buenas noches, quiero realizar la clasificación de usos de suelo de una determinada zona pero no sé cuál tipo de red es la más adecuada, ya que sólo cuento con 4 características como datos de entrada y la salida (o sea las clases de suelo) son mas de 50. Me gustaría que por favor me orientara. Muchas gracias de antemano.
Buenas, sino tienes mucho conocimiento en ello puedes irte a redes ya configuradas como pueden ser modelos que tiene Microsoft, Amazon, …
Buenas Noches, tengo una consulta a que tipo de red neuronal en cuanto a metodología, modelo y lenguaje debo usar para el procesamiento de imágenes capturadas mediante un dron.
Agradezco de antemano su ayuda.
Buenas te recomiendo que utilices metodologías ágiles de desarrollo, programes en Python o R. En cuanto a los modelos prueba con redes convolucionales y compara resultados para quedarte con el que mejor se ajuste.
Hola soy profesora de Software Quality Assurance y quiero investigar mas sobre como medir o asegurar la calidad de una red neuronal. Podrás recomendarme bibliografia al respecto?
Hola. Trabajo en un hospital y deseo calcular el ausentismo a turnos por un lado y la fecha problable de alta en internados por el otro. Para el ausentiemos pensaba en una red supervisada usando python y keras. Para calcular la fecha problable de alta de pacientes internados que me recomendarian?
Buenas quisiera encontrar (rellenar) datos faltantes de variables de temperatura en una base de datos histórica. Que redes neuronales me recomiendas. Se agradece de antemano su respuesta.