En este post vamos a mostrar la manera de invocar un SparkSession para escribir un fichero en disco mediante hfds.
Para ello toma como punto de partida el post Mi primera Apache Spark con Scala con Maven en Intelligent Idea.
En el paquete com.fer.cam se crea una Objeto denominado Main y se añade las siguientes lineas para crear el SparkSession:
//define warehouse
val warehouseDir = "file:${system:user.dir}/spark-warehouse"
//Creating Spark session:
val sparkSession=SparkSession.builder()
.master("local")
.appName("Apache SparK App")
.config("spark.sql.warehouse.dir", warehouseDir)
.getOrCreate()
Una vez creado el sparkSession vamos a utilizarlo para crear un RDD y guardar los datos en un fichero. Es necesario incluir la siguiente dependencia en el pom.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.1</version>
</dependency>
Como vimos en el post referenciado vuelve a ejecutar el proyecto con maven y se consigue un «BUILD SUCCESS» y ejecuta la aplicación.
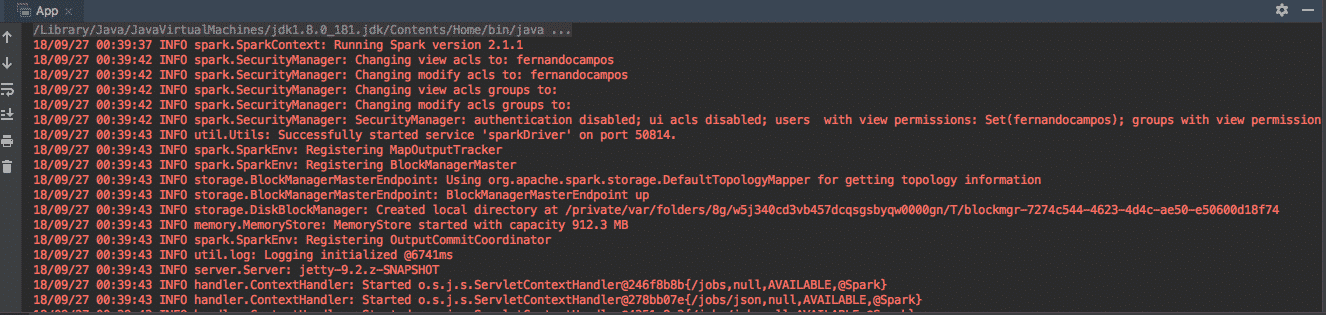
Ya tenemos disponible el SparkSession para crear un RDD que se rellena de datos aleatorios generados, se convierte en DataFrame y se salva en disco en formato JSON :
// Create a RDD val rdd = sparkSession.sparkContext.parallelize(Seq.fill(100){(Math.abs(Random.nextLong % 100L),Math.abs(Random.nextLong % 1000000000000L))})import sparkSession.implicits._val df2= rdd.toDF("duration" , "timestamp").cache()// URI Absolutaval path = "/../IdeaProjects/miprimeraAppScala2/src/main/resources/prueba.json"// Save el json file with overwrtting optiondf2.write.mode("overwrite").format("json").save(path)




0 comentarios