Temporal evolution graphic line
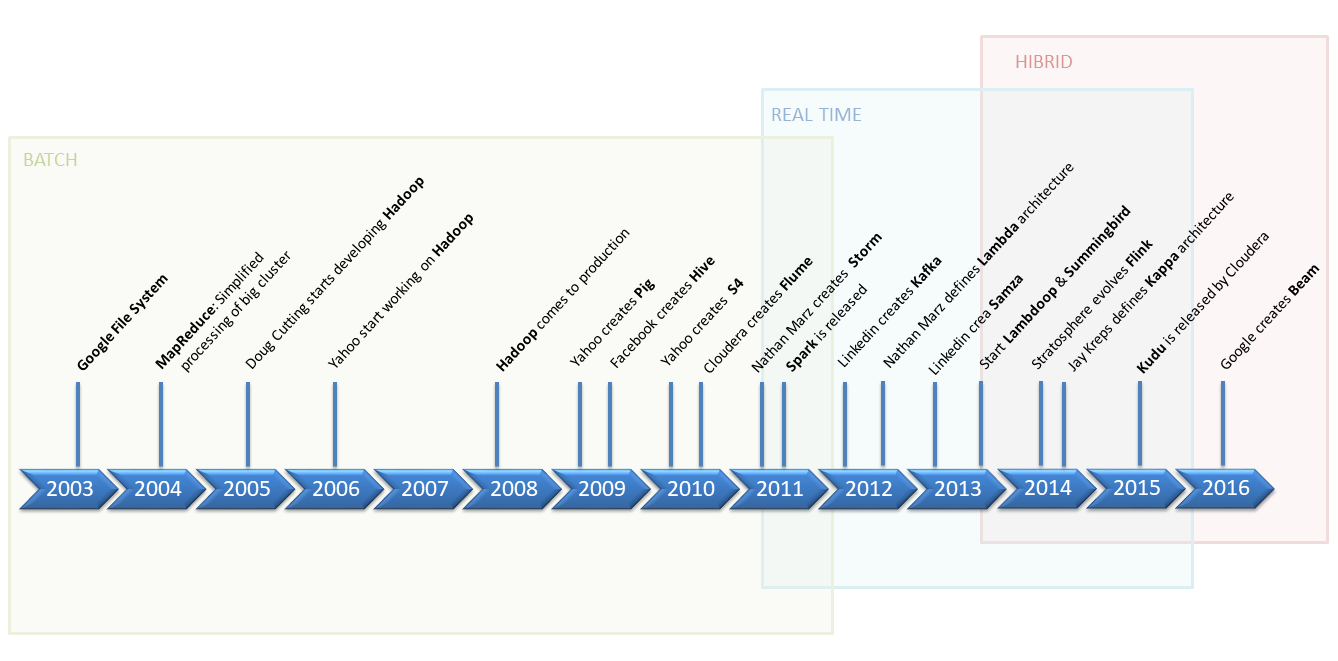
Temporal evolution of big data
Temporal evolution line
- 2003 – Google File System
- 2004 – MapReduce: Simplified processing of big clusters.
- 2005 – Doug Cutting starts developing Hadoop.
- 2006 – Yahoo starts working on Hadoop.
- 2008 – Hadoop comes to production.
- 2009 – Yahoo creates Apache Pig.
- 2009 – Facebook creates Apache Hive.
- 2010 – Yahoo creates Apache S4.
- 2010 – Cloudera creates Apache Flume.
- 2011 – Nathan March creates Apache Storm.
- 2011 – Apache Spark is released.
- 2012 – Linkedin creates Kafka.
- 2012 – Nathan March defines Lambda architecture.
- 2013 – Linkedin creates Samza.
- 2013 – Start Lambdoop and Summingbird.
- 2014 – Stratosphere evolves to Flink.
- 2014 – Jay Kreps defines Kappa architecture.
- 2015 – Kudu is released by Cloudera.
- 2016 – Google creates Beam.




0 Comments