Definición de Flume
![]()
![]() Apache Flume es un servicio distribuido que mueve de forma fiable y eficiente grandes cantidades de datos, especialmente logs. Ideal para aplicaciones de analíticas en línea en entornos Hadoop.
Apache Flume es un servicio distribuido que mueve de forma fiable y eficiente grandes cantidades de datos, especialmente logs. Ideal para aplicaciones de analíticas en línea en entornos Hadoop.
Flume tiene una arquitectura sencilla y flexible basada en flujos de datos en streaming, que permite construir flujos de múltiples por donde viajan los eventos a través de diferentes agentes hasta que alcanzan el destino final.
Características
- Perfectamente integrado en el ecosistema Hadoop, ejemplo de ello es la integración de Sink HDFS o HBase en Keberos.
- Especializado en datos de logs.
- Permite la recolección y agregación de logs de forma sencilla.
- Pensado para eventos simples, no para eventos complejos.
- Robusto y tolerante a fallos, con mecanismos de fiabilidad configurables y de conmutación por error y recuperación.
- Permite la lectura y escritura de multitud de fuentes de datos.
- Simplifica el filtrado y transformación de datos gracias a los interceptores.
- Dificultad de escalado horizontal, el añadir consumidores implica cambiar la topología del pipeline e añadir un nuevo destino.
- Soporta canales efímeros basados en memoria y canales duraderos basados en ficheros, por lo que no trabaja eficientemente para mensajes de larga duración puesto que los tiene que recuperar del agente.
- Los canales basados en ficheros no replican datos, por lo que están sujetos a errores de disco, para solventarlo se suelen replicar con RAIZ o SAN.
Arquitectura
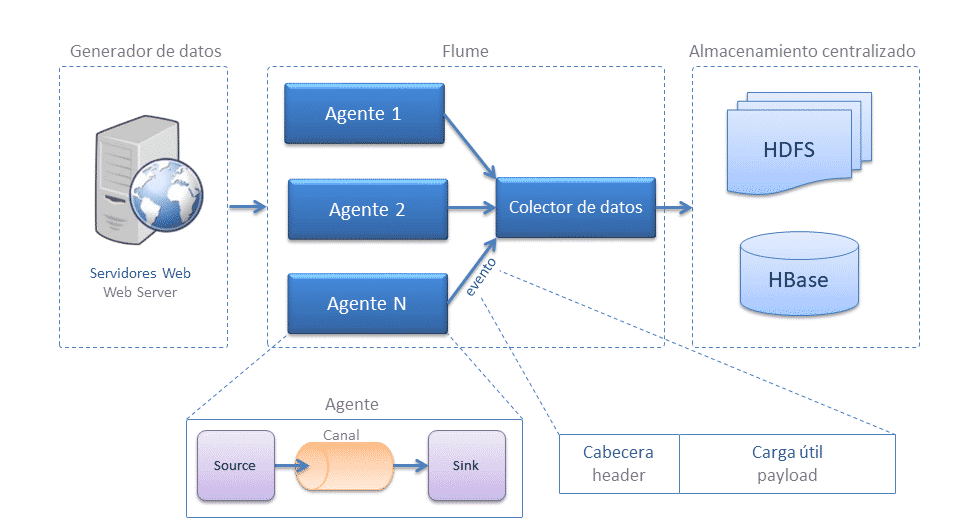
Arquitectura Apache Flume
- Evento: representa la unidad de datos en flume, cuenta de una carga de bytes y una cabecera opcional.
- Flujo de datos: describe el movimiento de eventos del origen al destino, cabe destacar que un evento puede pasar por agentes que de manera encadenada antes de llegar a su destino.
- Cliente: implementación de interfaz que opera en el punto de origen de los eventos y los entrega a los agentes. Los clientes suelen operar en el espacio de proceso de la aplicación de la que están consumiendo datos. Flume Log4j Appender es un ejemplo de cliente.
- Agente: es un proceso independiente que se encarga de recibir, guardar y enviar eventos, está compuesto por:
- Source: implementación de una interfaz que puede consumir eventos que le son enviados con un mecanismo específico y ponerlos en el canal. Avro es un ejemplo de interfaz.
- Canal: almacén transitorio de eventos. Los eventos se entregan al canal a través de las fuentes que operan en el agente. Un evento permanece en un canal permanece en el canal hasta que un receptor lo quite para su posterior transporte. JDBC es un ejemplo de canal que utiliza una base de datos incrustada respaldada por el sistema de archivos para conservar los eventos hasta que sean eliminados por un receptor.
- Sink: implementación de una interfaz que permite consumir eventos de un canal y transmitirlos al siguiente agente o a al destino final. Flume HDFS es un ejemplo de Sink.
Comparativa con otros sistemas como Kafka y RabbitMQ
Fuente: Web oficial




0 comentarios