Definición de Hadoop:
 Apache Hadoop es un sistema distribuido que permite realizar procesamiento de grandes volúmenes de datos a través de clúster, fácil de escalar.
Apache Hadoop es un sistema distribuido que permite realizar procesamiento de grandes volúmenes de datos a través de clúster, fácil de escalar.
A grandes rasgos se puede decir que Hadoop está compuesto por dos partes:
- Se ocupa del almacenamiento de datos de distintos tipos (HDFS)
- Realiza las tareas de procesamiento de los datos de manera distribuida (MapReduce).
Hadoop esta basado en una arquitectura maestro-esclavo o Master-Slave.
- El maestro en HDFS se les conoce como NameNode y se encargan de conocer como se encuentran los datos almacenados por el cluster.
- Los esclavos en HDFS se les conoce como DataNodes y se encargan de almacenar físicamente los datos en el cluster.
Arquitectura
Arquitectura básica
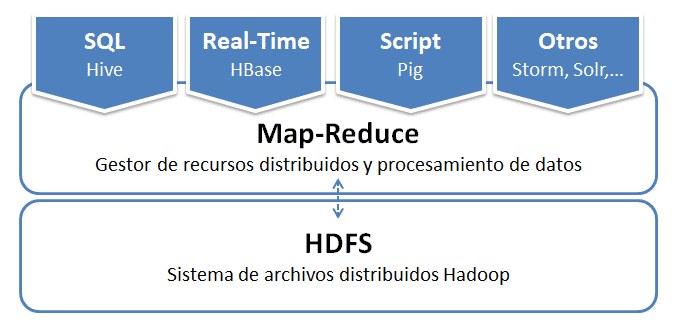
Arquitectura básica Hadoop
Acceso a datos: Hive, HBase, Pig, Storm, Solr, …
Map-Reduce (infraestructura de programación que proporciona algoritmos para realizar los cálculos distribuidos).
HDFS: Sistema de archivos.
Evolución de arquitectura con YARN
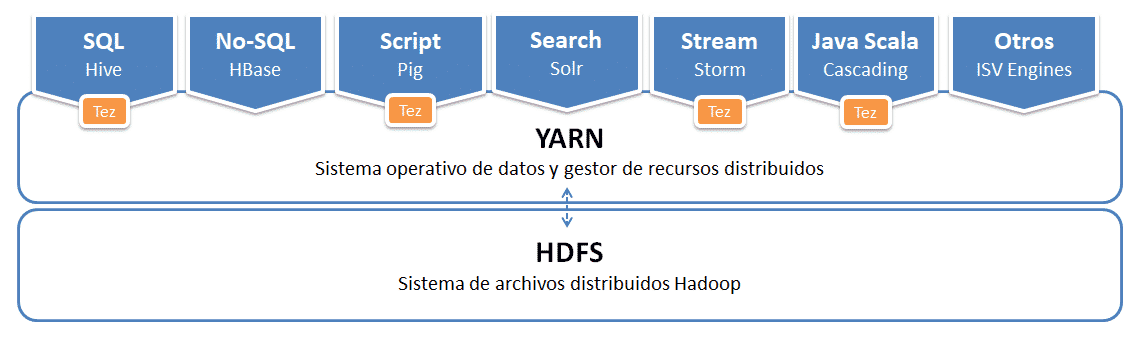
Arquitectura YARN Hadoop
Herramientas del ecosistema apache hadoop
Ingesta de datos
- Apache Kafka: sistema de intermediación de mensajes basado en el modelo publicador/subscriptor.
- Apache Flume: sistema de ingesta de datos semiestructurados o no estructurados en streaming sobre HDFS o HBase.
- Apache Nifi: es una herramienta ETL que se encarga de cargar datos de diferentes fuentes, los pasa por un flujo de procesos para su tratamiento, y los vuelca en otra fuente
Procesamiento datos
- Apache Hadoop Map-reduce: proporciona procesamiento de datos por lotes.
- Apache Storm: proporciona procesamiento de datos por lotes.
- Apache Samza: proporciona procesamiento de datos en tiempo real.
- Apache Tez: proporciona procesamiento de datos en tiempo real.
- Apache Spark Streaming: proporciona procesamiento de datos híbrido.
- Apache Flink: proporciona procesamiento de datos híbrido.
Transformación de datos
- Apache Hive: convierte las sentencias SQL o Pig en un trabajo de MapReduce.
- Apache Hue: proporciona una interfaz gráfica de navegador para realizar su trabajo Hive de forma sencilla.
- Apache Impala: alternativa a hive utilizada por Cloudera. Motor de consultas SQL para el procesamiento masivo en paralelo (MPP) de los datos almacenados en un clúster Hadoop.
- Apache Sqoop: proporciona transferencia bidireccional de datos entre Hadoop y una bases de datos SQL (datos estructurados)
- Apache Pig: lenguaje de alto nivel para realizar codificación MapReduce. Convierte una descripción de alto nivel de cómo deben ser procesados los datos en “Jobs” de MapReduce, sin necesidad de tener que escribir largas cadenas de jobs cada vez, mejorando la productividad de los desarrolladores.
- Apache Nifi: es una herramienta ETL que se encarga de cargar datos de diferentes fuentes, los pasa por un flujo de procesos para su tratamiento, y los vuelca en otra fuente.
Almacenamiento
- HDFS: sistema de almacenamiento por escelencia de Hadoop.
- Apache HBase: sistema de gestión de bases de datos orientado a columnas.
- Apache Kudo: gestor de alamcenamiento de bases de datos orientado a columnas para Cloudera.
Visualización de datos
- Apache Zeppelin: notebook similar a Jupiter para visualización rapida de datos.
Seguridad
- Apache Ranger es un marco para habilitar, monitorear y administrar seguridad de datos integral en toda la plataforma Hadoop.
- Apache Sentry es un sistema para aplicar la autorización basada en funciones de granularidad fina a datos y metadatos almacenados en un clúster de Hadoop.
- Knox es una aplicación Gateway para interactuar con las API REST y las IU de Apache Hadoop.
- Kerberos es un protocolo de autenticación que permite a dos ordenadores demostrar su identidad mutuamente de forma segura.
Machine learning
- Apache Mahout: marco de álgebra lineal distribuido y Scala DSL matemáticamente expresivo, diseñado implementen rápidamente algoritmos.
- Spark MLlib: librería de machine learning, que contiene la API original construido sobre los RDD.
- SparkML: librería de machine learning, que proporciona un API de nivel superior construido sobre DataFrames.
- FlinkML: librería de machine learning para Flink.
Etiquetado de datos
- Apache Falcon
- Apache Atlas




0 comentarios