Prerequisitos

Limpiar todos los hdfs generados, utilizando la linea de comandos
hdfs dfs -rm -r /streaming hdfs dfs -mkdir /streaming hdfs dfs -ls /streaming
Generar datos usados para iniciar el análisis
Se genera una serie de datos en formato json que se almacenan en un fichero hdfs.
val events = sc.parallelize(
"""
[{"accion":"Abrir", "tiempo":"2018-08-01T00:01:17Z"},
{"accion":"Cerrar","tiempo":"2018-08-01T00:01:17Z"},
{"accion":"Abrir", "tiempo":"2018-08-02T00:01:17Z"},
{"accion":"Abrir", "tiempo":"2018-08-02T00:01:17Z"},
{"accion":"Abrir", "tiempo":"2018-08-03T00:01:17Z"},
{"accion":"Cerrar","tiempo":"2018-08-03T00:01:17Z"},
{"accion":"Abrir", "tiempo":"2018-08-03T00:01:17Z"}]
""" :: Nil)
val df = sqlContext.read.json(events)
df.write.mode("overwrite").format("json").save("/streaming/events_diego1.json")
Definir la lectura en tiempo real
import org.apache.spark.sql.functions._
val inputPath = "/streaming/*.json"
val jsonSchema = new StructType().add("accion", StringType).add("tiempo", TimestampType)
val streamingInputDF =
spark
.readStream // Usado para lecturas en tiempo real
.schema(jsonSchema) // Definir el esquema json a utilizar
.option("maxFilesPerTrigger", 1) // Tratar las secuencias de archivos seleccionando una por vez
.json(inputPath
Definir la consulta
// Definir la consulta como si fuera estática val streamingCountsDF = streamingInputDF .groupBy($"accion", window($"tiempo", "1 day")) .count() // Comprobar que la estructura de datos es de tiempo real streamingCountsDF.isStreaming
Establecer la configuración de flujo de datos del cluster
spark.conf.set("spark.sql.shuffle.partitions", "1") // mantener el tamaño de las mezclas pequeñasval query =
streamingCountsDF
.writeStream
.format("memory") // almacena la tabla de memoria (en Spark 2.0)
.queryName("mi_tabla") // nombre de la tabla generada
.outputMode("complete") //todos los recuentos deben de estar en la tabla
.start()
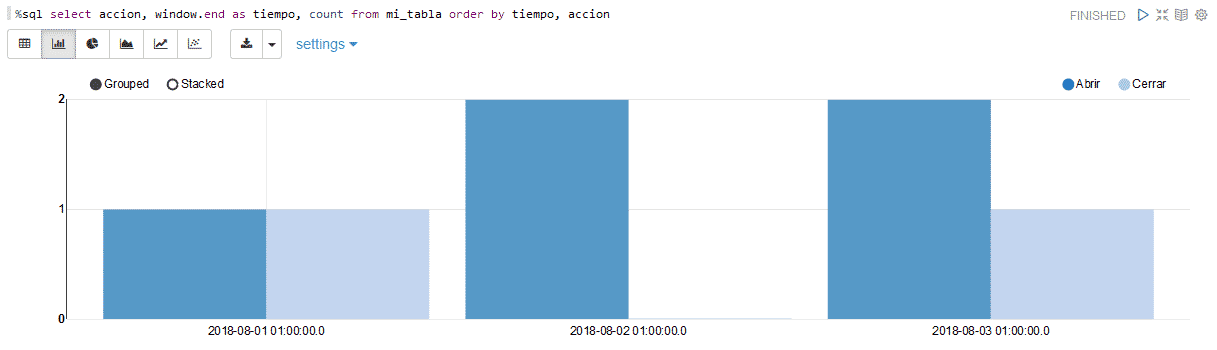
Visualizar los datos almacenados hasta el momento
%sql select accion, window.end as tiempo, count from mi_tabla order by tiempo, accion
Generar nuevos datos a incluir en el análisis
[{"accion":"Abrir", "tiempo":"2018-08-04T00:01:17Z"},
{"accion":"Cerrar","tiempo":"2018-08-04T00:01:17Z"},
{"accion":"Abrir", "tiempo":"2018-08-04T00:01:17Z"},
{"accion":"Abrir", "tiempo":"2018-08-05T00:01:17Z"},
{"accion":"Abrir", "tiempo":"2018-08-05T00:01:17Z"},
{"accion":"Cerrar","tiempo":"2018-08-06T00:01:17Z"},
{"accion":"Abrir", "tiempo":"2018-08-06T00:01:17Z"}]
""" :: Nil)
val df = sqlContext.read.json(events)
df.write.mode("overwrite").format("json").save("/streaming/events_diego2.json")
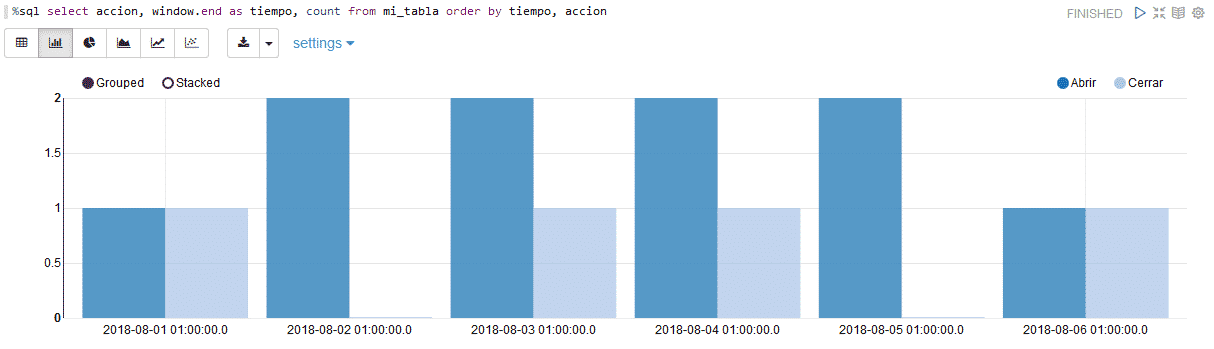
Visualizar los datos acumulados
%sql select accion, window.end as tiempo, count from mi_tabla order by tiempo, accion




0 comentarios