RESUMEN:
El objetivo es aplicar un método de organización utilizado en la rama del aprendizaje no supervisado, en él se infieren modelos con el objetivo de extraer conocimiento de un conjunto de datos (en este caso un conjunto de muestras de audio) aplicando una técnica llamada «reducción de la dimensionalidad», gracias a la cual no es necesario saber si existe o no una relación entre los elementos del conjunto y el tiempo.
El método de clasificación se realiza a mediante del escalamiento multidimensional (MDS), este nos permite visualizar el nivel de similitud de cada uno de los elementos de manera individual que pertenezcan a un conjunto, es una de las formas de reducción de dimensión no lineal.
Esta técnica de escalamiento multidimensional se llevará a cabo mediante el análisis frecuencial previo de cada uno de los elementos del conjunto obteniendo la diferencia o similitud entre las muestras de nuestro conjunto a nivel frecuencial.
El algoritmo MDS tiene como objetivo colocar cada objeto en un espacio N-dimensional para que las dis-
tancias entre los objetos se mantengan de la mejor manera posible, mas tarde, a cada objeto se le asignan
coordenadas en cada una de las N dimensiones permitiendo visualizar el resultado.
INSPIRACIÓN:
En el contexto audiovisual existe un perfil profesional que es el diseñador de sonido. Este es un profesional por
lo general independiente que se dedica a la creación de efectos sonoros con el objetivo de narrar, personificar,
generar emociones, retratar espacios sonoros, épocas. En definitiva crear un universo sonoro con una
identidad particular dentro del contexto en el que está trabajando.
El resultado de esta labor es un trabajo metódico y artesanal donde el volumen de archivos de sonido que
se genera para el desarrollo de un proyecto suele ser muy grande, por lo que es muy fácil que esto ocasione una perdida
de «perspectiva tímbrica» en el proceso creativo, pues a mayor volumen de muestras, es fácil que los sonidos
acaben siendo demasiado parecidos y como consecuencia la originalidad del trabajo puede verse mermada.
Por tanto el desarrollo de una herramienta que analice las muestras (únicamente desde la perspectiva frecuencial) en las que el profesional que está trabajando y ahorraría mucho tiempo a la hora de tomar decisiones de carácter creativo, pues definiría la predominancia frecuencial del conjunto de muestras y por tanto tendría una visión clara de cuál es el carácter tímbrico del grupo de muestras.
La solución para conseguir tal fin es la aplicación de una de las técnicas de análisis predictivo con Machine Learning concretamente la que hace referencia al escalamiento multidimensional.
El objetivo es la implementación de una de las técnicas de ML de la manera mas original posible evitando la dependencia de data sets y aplicado un campo como es el audio en el que me siento cómodo.
SOLUCIÓN PLANTEADA:
- Tomar unas muestras como referencia y analizar el contenido frecuencial de las mismas.
- Definir un modelo:
• 2.1 Crear la matriz de similitud.
• 2.2 Calcular las distancias entre los elementos.
• 2.3 Ejecutar un escalado multidimensional. - Evaluar el modelo:
• 3.1 Visualización en un sistema de coordenadas.
La metodología utilizada se basará inicialmente en la comparación de un conjunto de muestras (.WAV) a ser posible de la misma duración de tiempo, el conjunto del ejemplo lo formaban 172 muestras de audio.
Para llevar a cabo el proyecto se relacionó las muestras de sonido con el ejemplo de escalamiento multidimensional, y fué necesario el uso de warbleR, una biblioteca de funciones en que tiene por objeto facilitar el análisis de la estructura de señales acústicas de animales.
CODIGO:
## INSTALAMOS LAS LIBRERIAS
library(imager)
library(tuneR)
library(knitr)
library(NatureSounds)
library(seewave)
library(warbleR)
library(igraph)
library(ggplot2)
library(ggfortify)
## CARGAMOS LAS MUESTRAS
Cargamos las muestras de audio en una tabla.
alles_dir <- «RUTA_DONDE_SE_ENCUENTREN_LAS_MUESTRAS_DE_AUDIO»
wav_names <- list.files(alles_dir, pattern = «\\.wav$»)
sound_design <- selection_table(whole.recs = TRUE, path = alles_dir, extended = TRUE)
Debido a que la tabla es mayor de ~58MB nos aparecerá un mensaje en cónsola preguntandonos si queremos continuar. Le decimos «y».
> sound_design <- selection_table(whole.recs = TRUE, path = alles_dir, extended = TRUE)
checking selections (step 1 of 2):
|++++++++++++++++++++++++++++++++++++++++++++++++++| 100% elapsed=01s
all selections are OK
Expected ‘extended_selection_table’ size is ~58MB (~0.05669 GB)
Do you want to proceed (y/n):
La muestras se cargarán en la tabla que antes habíamos creado:
saving wave objects into extended selection table (step 2 of 2):
|++++++++++++++++++++++++++++++++++++++++++++++++++| 100% elapsed=03s
2. Definimos el modelo:
En el procesamiento de señales, la correlación cruzada (o a veces denominada «covarianza cruzada») es una medida de la similitud entre dos señales, en función del tiempo es frecuentemente usada para encontrar características relevantes en una señal desconocida por medio de la comparación con otra que sí se conoce. Este caso lo que se pretende es hacer es comparar todo el conjunto consigo mismo.
El cepstrum de frecuencia de mel (MFC) es una representación del espectro de potencia a corto plazo de un sonido, basado en una transformación coseno lineal de un espectro de potencia logarítmica en una escala de frecuencia de mel no lineal.
2.1 Creamos la matríz de similitud (xcor).
xcor <- xcorr(sound_design, bp = c(0, 20), wl = 512, ovlp = 99, path = alles_dir,
type = «mfcc», method= 1, na.rm = TRUE,
parallel = 4
Vemos como primero se crean las matrices (manteniéndolas internamente como lista) y a continuación se calcula la correlación cruzada en segundo paso.
Nota: parallel = 4 hace referencia a la cantidad de nucleos del procesador, por lo que es un parámetro que puede modificarse en el caso de que dispongamos de más núcleos en el procesador.
creating MFCC matrices (step 1 of 2):
|++++++++++++++++++++++++++++++++++++++++++++++++++| 100% elapsed=11s
running cross-correlation (step 2 of 2):
|++++++++++++++++++++++++++++++++++++++++++++++++++| 100% elapsed=04m 18s
2.2 Calculamos las distancias entre los elementos.
Medida de distancia especificada para calcular las distancias entre las filas de una matriz de datos.
distancia <- dist(xcor, method = «euclidean»)
2.3 Ejecutamos el escalamiento multidimensional (MDS) de la matriz de datos, también conocido como análisis de coordenadas principales.
valores <- cmdscale(distancia, eig = T)
3 Evaluamos el modelo:
3.1 Visualización en un sistema de coordenadas, haciendo uso de autoplot ya que utiliza ggplot2 para representar un gráfico particular de un objeto de una clase particular en un solo comando.
autoplot(cmdscale(distancia, eig = T), label = TRUE, label.size = 3, frame = TRUE)
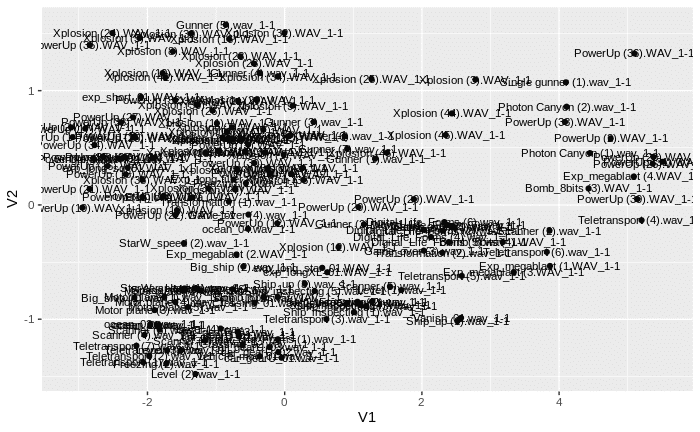
Y este el resultado final.
Se puede apreciar como el modelo clasifica las muestras en función de la frecuencia y puede verse la predominancia de unos 4 grupos que constituyen el conjunto de muestras.
Si os apetece comprobar el funcionamiento, dejo el enlace a las muestras con las que he llevado a cabo el ejemplo.
Nota: Las muestras corresponden a una colección personal de sonidos de 8 bits y son copyleft.





0 comentarios