Before we focus on the Lambda architecture it is advisable to specify the two types of data processing that compose it:
The processing of data in batch mode, is one that allows us to process data volumes in spaced times, for example every 10 minutes, 1 hour or daily. For this the system has batches or batch in which it stores all the information that it is obtaining until completing a period.
An example of this type of processing can be the sales transactions of the product over a period on which to perform the processing. If the volume of data is high, this processing may take several minutes or even hours, and in this particular case it is likely that decision makers will be willing to wait for that time to do so.
Data processing in stream mode or semi-real time, is one that needs to process data volumes in times as close to real time as possible, we talk about orders of 100 milliseconds to seconds.
A typical example of this type of processing can be the stock trading in which an instant of time can be crucial when making a decision.
Lambda architecture combines data processing: “Batch” and “stream”, looking for the advantages that each one of them offers.
This architecture has been developed enormously with the arrival of the big dated that provides a low cost solution for complex processing problems.
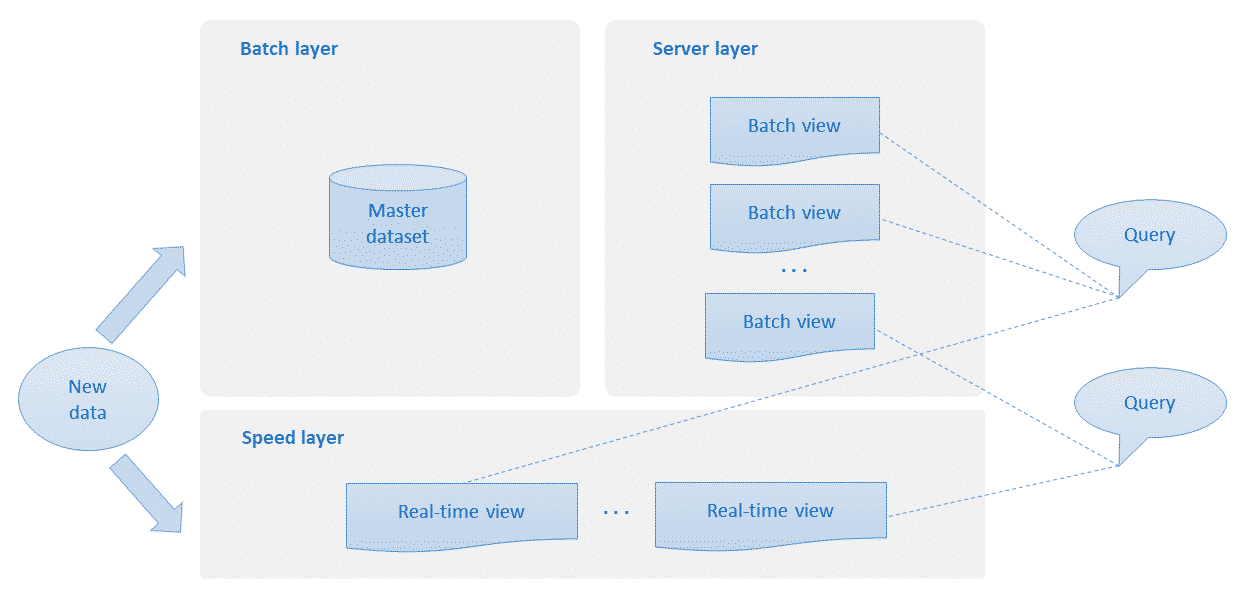
Lambda architecture




0 Comments