Components
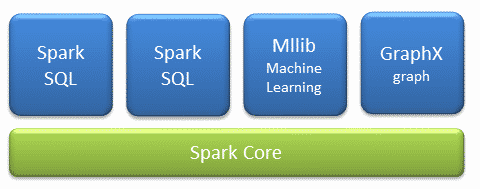
Spark components
Spark Core
Spark core is the core where all the architecture is supported, provides:
- Distributing tasks
- Programming
- Input/output operations
Using Java, Python, Scala and R programming interfaces focused on RDDs’s abstraction.
It establishes a functional model that allows to perform invoke operations in parallel like map, filter or reduces on a RDD, for it is passed a function to Spark, which plans the execution in parallel on the cluster.
Spark SQL
Spark SQL introduces a concept of data abstraction called SchemaRD, which provides support for structured and semi-structured data.
The data can be manipulated using:
- Specific language such as Scala, Java and Python.
- ODBC/JDBC connectors.
Spark Streaming
Spark streaming is the layer in charge of real-time data analysis.
It does ingest data in mini-batches, this has the advantage that it can also be used for batch analysis, although it has the disadvantage that the latency is somewhat higher than the size of the mini-branch.
There are other streaming engines that process event by event instead of mini lots like Storm and Flink.
MLlib
MLLib is the automatic learning layer distributed on the core, which provides the automatic learning famework where you can find multitude of algorithms of classification, regression, cluster analysis, reduction of dimensionality and statistics Descriptive.
By having an architecture in memory, it provides greater speed of operation, one speaks of around 9 times faster than Apache Mahout.
GraphX
GraphX is the graphical processing layer distributed over the core. Based on immutable RDDs, graphics do not allow updating.
Source: spark.apache.org




0 Comments