Download
Installation
First install virtual box and once installed go to the virtual machine of Hortonworks and run it, this will appear an installation of this machine in virtual box.
Configure the features of the machine, comment that minimally needs 8GB of RAM.
Hortonworks Configuration
Once the machine is ripped we will get an HTTP in the shell indicating the Web path to access. http://127.0.0.1:8888 Example
Note: In the version HDP 2.6.5 path is http://127.0.0.1:8080
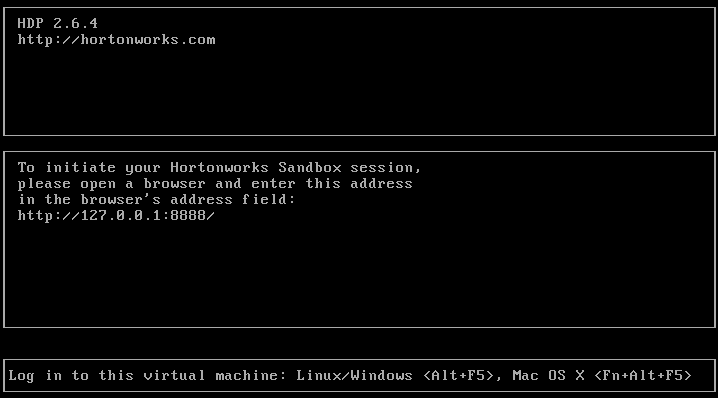
Accessing the browser will get the following Web.
 Once here we can access directly to “NEW to HDP” with user/pass = raj_ops/Raj_ops or “ADVANCED HDP” and in each one of the services you can see the user and the default key.
Once here we can access directly to “NEW to HDP” with user/pass = raj_ops/Raj_ops or “ADVANCED HDP” and in each one of the services you can see the user and the default key.
Interpreter settings (Python or Scala)
Enter Zeppelin (http://127.0.0.1:8080) and at the top right there is a configuration icon to configure the interpreters.
Once there modify the Python path so that the system is able to find it.
Use with Zeppelin
Zeppelin provides a notebook (type Jupiter) where we can execute our code in different languages, just indicate in the first line the interpreter to use:
%spark2 => para scala
%spark2.pyspark => para python




0 Comments