Formato: Textfile
El formato Textfile es el formato de almacenamiento más simple de todos y es el predeterminado para tablas en sistemas Hadoop.
No es más que texto plano donde los campos se almacenan separados por un delimitador y cada registro es separado por una línea.
Dentro de este formato dependiendo de la estructura de los delimitadores podemos tener CVS, TSV, JSON Records, …
Este formato es legible por el ser humano e interpretable por la mayoría de las herramientas.
Los datos en este formato ocupan mucho y no son eficientes para consultar.
Este tipo no soporta compresión.
Formato: Sequence File – Archivo de secuencia
El formato Sequence File es el formato de almacenamiento proporciona una estructura de datos persistente para pares clave-valor binarios.
Acaba con la problemática del formato TextFile donde el texto no puede tener los caracteres delimitadores.
Se suele utilizar para transferencias de datos entre trabajos de Map-Reduce, ya que son fácilmente divisibles.
Los tipos de compresión recomendados con este formato son:
- snappy
- gzip
- deflate
- bzip2
Formato: Parquet
El formato Parquet es un formato open-source de almacenamiento en columnas para Hadoop.
Fue creado para poder disponer de un formato libre de compresión y codificación eficiente.
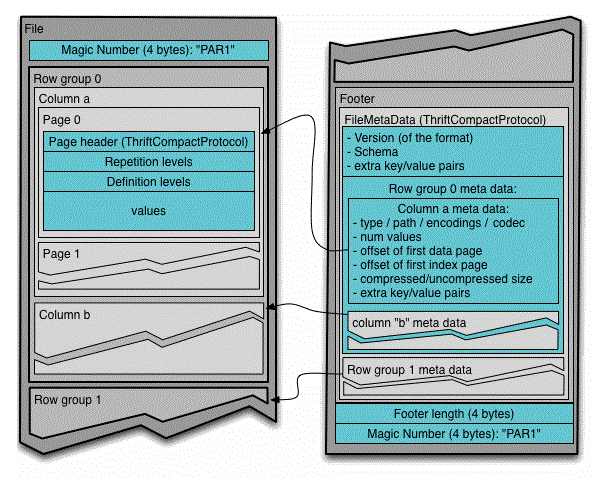
estructura de ficheros parquet
El formato de Parquet está compuesto por tres piezas:
- Row group: es un conjunto de filas en formato columnar, con un tamaño entre 50Mb a 1Gb.
- Column chunk: son los datos de una columna en un grupo. Se puede leer de manera independiente para mejorar las lecturas.
- Page: Es donde finalmente se almacenan los datos debe ser lo suficiente grande para que la compresión sea eficiente.
En entornos YARN es necesario indicar cuánta memoria puede utilizar un nodo para asignar recursos con el parámetro.
Los tipos de compresión recomendados con este formato son:
- snappy (valor predeterminado)
- gzip
Fuente: Web Oficial
Formato: Avro
El formato Parquet es un formato open-source utilizado para la serialización de datos.
Este formato es fruto del proyecto Apache Avro, que es un sistema de compresión diseñado para la serialización de datos que proporciona estructuras de datos complejas, con un formato binario, compacto y rápido.
La base fundamental del formato son los esquemas. Siempre que se lee un formato .avro está presente el esquema con el que han sido escritos, esto permite aumentar el rendimiento al escribir los datos, haciendo la serialización rápida y viable en espacio.
Los esquemas de Avro están definidos en JSON para facilitar la implementación con los lenguajes de programación.
También indicar que soporta evolución de esquemas.
Los tipos de compresión recomendados con este formato son:
- snappy
- gzip
- deflate
- bzip2
Formato: ORC (Optimized Row Columnar)
El formato ORC es un formato que almacena colecciones de filas en un archivo y dentro de la colección en la que están almacenados los datos de fila en un formato de columnas. Esto permite el proceso paralelo de colecciones de filas en un clúster.
El formato utiliza codificadores específicos de tipo para cada columna y divide el archivo en grandes bandas.
Las bandas utilizan índices que permiten a los lectores de Big SQL saltar grandes conjuntos de filas que no cumplen la condición de filtro.
También resaltar que ORC es un formato columnar autodescriptivo y sin tipo, diseñado para carga de trabajos en Hadoop.
Los tipos de compresión recomendados con este formato son:
- zlib (el valor predeterminado)




Buenas, creo que tienes una errata:
Formato: Avro
El formato Parquet es un formato open-source utilizado para la serialización de datos.
Te refieres a formato Avro, no parquet, no?
Felicitarte por los tutoriales, suelen ser muy muy claros y concisos.
Gracias
Es correcta la afirmación de alfonso, ya que Avro al ser un formato el cual la estructura esta en json, permite la serializacion de datos.