Uso: Clasificador lineal.
Descripción: El análisis de la regresión es una técnica estadística para estimar las relaciones que existen entre variables.
En este modelo se fija la variable que se quiere predecir (variable dependiente) y se determina la relación con el resto de variables predictoras (independientes)
En la regresión lineal múltiple existe más de una variable independiente que predice el comportamiento de la variable dependiente.
Variable dependiente: Métrica.
Variables independientes: Métricas y/o no métricas.
Ejemplo en R: Determinar el tiempo necesario para organizar diferentes bloques de cajas que se encuentran a diferentes distancias.
# Carga de datos
datos <- read.table("https://www.diegocalvo.es/wp-content/uploads/2016/09/datos-regresion-lineal-multiple.txt", header = TRUE)# Explorar la relación entre todas las parejas de variables pairs(datos)
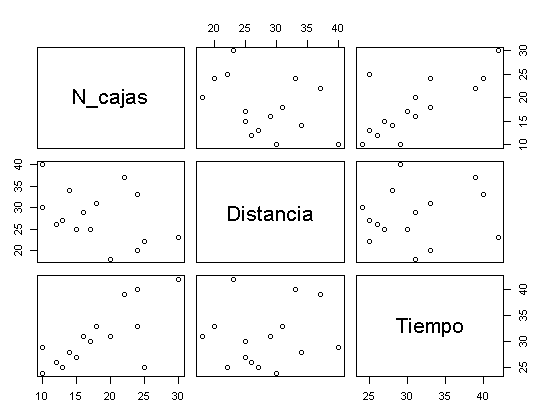
# Calcular la intensidad de la relación mediante un análisis de correlación. cor(datos)
N_cajas Distancia Tiempo N_cajas 1.0000000 -0.4052976 0.7246466 Distancia -0.4052976 1.0000000 0.1269032 Tiempo 0.7246466 0.1269032 1.0000000
# Mostramos visualmente la relación de la variable dependiente con cada una de las variables independientes plot(datos$Tiempo,datos$N_cajas) plot(datos$Tiempo,datos$Distancia)
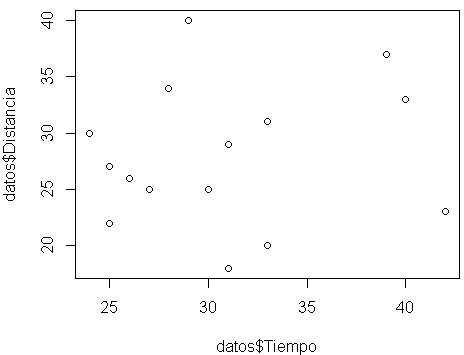
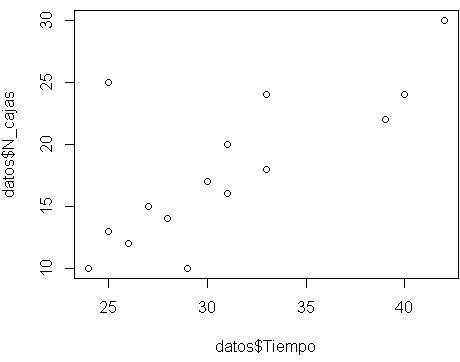
# A partir de los análisis realizados se opta por realizar un modelo múltiple lineal del tipo y = ax1 + bx2 + c
modelo1<- lm(datos$Tiempo~datos$N_cajas+datos$Distancia, data=datos) summary(modelo1)
Call:
lm(formula = datos$Tiempo ~ datos$N_cajas + datos$Distancia,
data = datos)
Residuals:
Min 1Q Median 3Q Max
-9.2716 -0.5405 0.5212 1.4051 2.9381
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.3112 5.8573 0.395 0.70007
datos$N_cajas 0.8772 0.1530 5.732 9.43e-05 ***
datos$Distancia 0.4559 0.1468 3.107 0.00908 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.141 on 12 degrees of freedom
Multiple R-squared: 0.7368, Adjusted R-squared: 0.6929
F-statistic: 16.8 on 2 and 12 DF, p-value: 0.0003325
# A partir de esta análisis deducimos que el modelo queda: Tiempo = 0,8772*N_cajas + 0,4559*Distancia + 2,3112 + error formula(modelo1)
# Fijándonos en R cuadrado (0,7368) vemos que el modelo no estima con precisión y vamos a probar a eliminar una variable para ver si mejora su precisión.
# Nuevo modelo: Tiempo = a*N_cajas + b + error
modelo2 <- lm(datos$Tiempo~datos$N_cajas, data=datos) summary(modelo2)
Call:
lm(formula = datos$Tiempo ~ datos$N_cajas, data = datos)
Residuals:
Min 1Q Median 3Q Max
-10.6583 -1.6018 -0.1821 2.5262 5.3952
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 18.5452 3.4142 5.432 0.000115 ***
datos$N_cajas 0.6845 0.1805 3.791 0.002244 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.053 on 13 degrees of freedom
Multiple R-squared: 0.5251, Adjusted R-squared: 0.4886
F-statistic: 14.37 on 1 and 13 DF, p-value: 0.002244# Analizados los dos modelos vemos que el modelo primero ajusta mejor que el segundo # Para comparar ambos modelos se recurre al análisis ANOVA anova(modelo2,modelo1)
Analysis of Variance Table Model 1: datos$Tiempo ~ datos$N_cajas Model 2: datos$Tiempo ~ datos$N_cajas + datos$Distancia Res.Df RSS Df Sum of Sq F Pr(>F) 1 13 213.57 2 12 118.38 1 95.198 9.6505 0.009079 ** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
# Viendo el resultado podemos concluir que el modelo que mejor se ajusta es el modelo más complejo = modelo1
# Para que este modelo sea fiable debemos realizar un ANALISIS DE RESIDUOS
# SUPUESTO 1: Los errores deben seguir una distribución normal
residuos<-rstandard(modelo1) # residuos estándares del modelo ajustado (completo) win.graph() # abre una ventana para los gráficos par(mfrow=c(1,3)) # divide la ventana en una fila y tres columnas hist(residuos) # histograma de los residuos estandarizados boxplot(residuos) # diagrama de cajas de los residuos estandarizados qqnorm(residuos) # gráfico de cuantiles de los residuos estandarizados qqline(residuos)
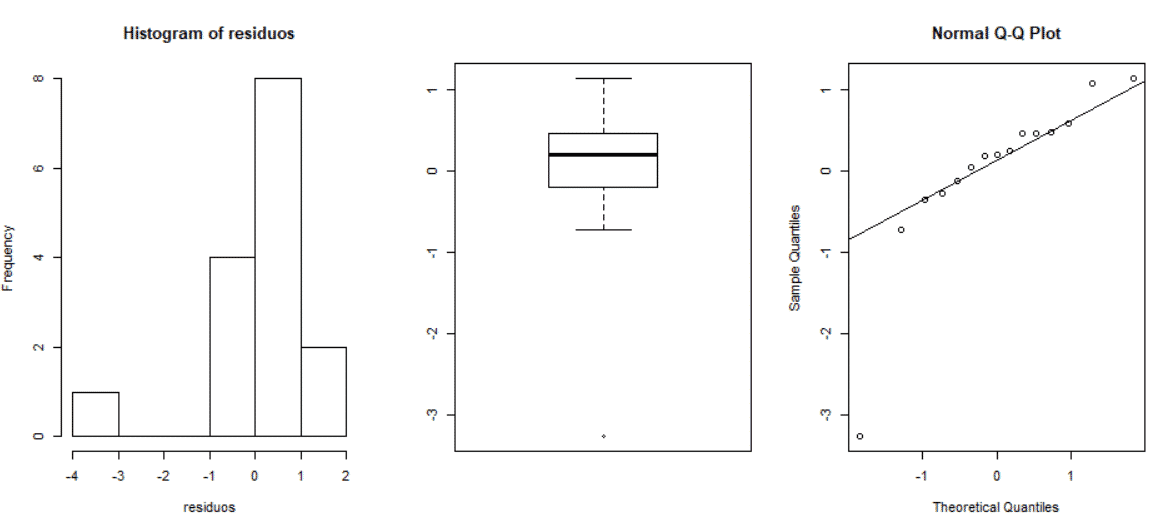
Estudio de los residuos
# SUPUESTO 2: La varianza de los errores es constante
plot(fitted.values(modelo1),rstandard(modelo1), xlab="Valores ajustados", ylab="Residuos estandarizados") # gráfico 2D de los valores ajustados vs. los residuos estandarizados abline(h=0) # dibuja la recta en cero
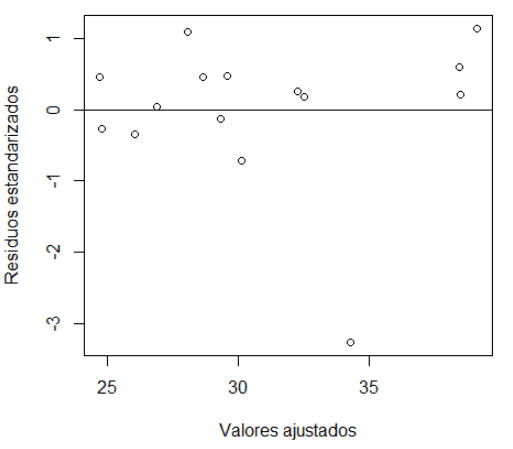
Estudio de la varianza de los errores
# SUPUESTO 3: La independencia de los errores
plot(datos$N_cajas,rstandard(modelo1),xlab="N_cajas",ylab="Residuos estandarizados") plot(datos$Distancia,rstandard(modelo1),xlab="Distancia",ylab="Residuos estandarizados")
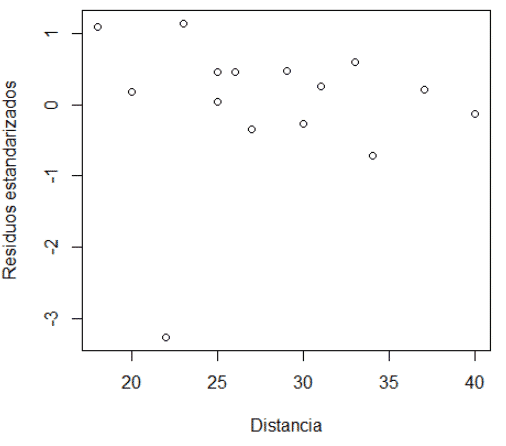
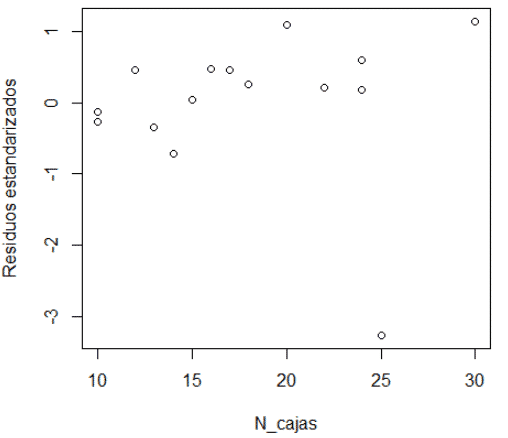




Diego, donde podemos encontrar base de datos para practicar con regresión múltiple
En la propia ayuda de R tienes multitud de ejemplos
Aunque también puedes probar con https://www.kaggle.com, en esta web tienes multitud de bases de datos libres con retos para resolver.
Un saludo
Muchísimas gracias Diego por compartir tu conocimiento.
Excelente explicación, muy clara.
Me alegro mucho de recibir este tipo de comentarios.
Un saludo
Gracias por el ejemplo, Diego. Ahora bien, yo necesito correr una regresion multiple donde la variable endogena esta rezagada un periodo, solo que no encuentro con que codigo hacerlo. Conoces alguno?
Buenas Raul, no conozco ninguno para regresión lineal, probablemente te venga mejor utilizar series temporales.
> gift summary gift
Error: unexpected symbol in «summary gift»
> summary (gift)
Call:
lm(formula = Species ~ Area + Elevation + Nearest + Scruz + Adjacent,
data = gala)
Residuals:
Min 1Q Median 3Q Max
-111.679 -34.898 -7.862 33.460 182.584
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.068221 19.154198 0.369 0.715351
Area -0.023938 0.022422 -1.068 0.296318
Elevation 0.319465 0.053663 5.953 3.82e-06 ***
Nearest 0.009144 1.054136 0.009 0.993151
Scruz -0.240524 0.215402 -1.117 0.275208
Adjacent -0.074805 0.017700 -4.226 0.000297 ***
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 60.98 on 24 degrees of freedom
Multiple R-squared: 0.7658, Adjusted R-squared: 0.7171
F-statistic: 15.7 on 5 and 24 DF, p-value: 6.838e-07
> summary (gift)
Call:
lm(formula = Species ~ Area + Elevation + Nearest + Scruz + Adjacent,
data = gala)
Residuals:
Min 1Q Median 3Q Max
-111.679 -34.898 -7.862 33.460 182.584
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.068221 19.154198 0.369 0.715351
Area -0.023938 0.022422 -1.068 0.296318
Elevation 0.319465 0.053663 5.953 3.82e-06 ***
Nearest 0.009144 1.054136 0.009 0.993151
Scruz -0.240524 0.215402 -1.117 0.275208
Adjacent -0.074805 0.017700 -4.226 0.000297 ***
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 60.98 on 24 degrees of freedom
Multiple R-squared: 0.7658, Adjusted R-squared: 0.7171
F-statistic: 15.7 on 5 and 24 DF, p-value: 6.838e-07
buenas noche Raul.. ejecute la anterior sentencia y no comprendo el resultado . es posible que usted me de su opinion a cerca de este resultado.
le agradezco
Muchas gracias por el aporte, es muy claro y sencillo de seguir, soy súper principiante en R y pude lograrlo.
Gracias
Hola Diego, excelente página. El mejor modelo para estos datos es sin termino independiente! No le prestaste atención a los p-valores de cada parámetro, esos corresponden a la prueba de hipótesis, donde la hipótesis nula corresponde a el parametro betai = 0.
Hola Diego, una duda necesito hallar el coeficiente de correlación múltiple de una variable especifica de un ML múltiple. Sabes como se hace en R?. Gracias
Buenas Mary,
Echa un vistado al post que tengo de correlación entre variables: https://www.diegocalvo.es/correlacion-entre-variables-en-r/
Hola diego, gracias por el ejemplo. Tengo una sola pregunta, si tuvieras que dar la formula final:
Tiempo = 0,8772*N_cajas + 0,4559*Distancia + 2,3112 + error..
Ese valor de error, cual seria?
Buenas Rocio.
En la formula debes de sustituir el N_cajas y Distancia por su valor realizando las cuentas obtendrías el tiempo
Hola, Diego. Muchas gracias por tan valiosa información.
Me queda una duda: ¿qué pasa cuando el valor p del intercepto es menor a 0.05? (en el caso del modelo 1 es 0.70007)
Muchas gracias,
Hola, Diego.
El comentario anterior quedó mal escrito, la pregunta es: ¿qué pasa cuando el valor p del intercepto es MAYOR a 0.05?
Muchas gracias,
Como puedo hacer una regresion multivariable, con series de fourier en R?