Definición de Big Data
El termino big data o datos masivos hacer referencia a un volumen de datos que superaba las capacidades del software habitualmente usado para ver capturar, administrar y procesar datos.
Como la capacidad de computo es cada vez más elevada y la cifra a partir de la que se considera un conjunto de datos como big data va en aumento, en 2012 ya se fijaba la frontera en 12 terabytes.
Todo esto no hubiera sido posible sino fuera por Hadoop, un sistema que permite implementar sobre hardware a un costo relativamente bajo, para el análisis de grandes volúmenes de datos de los tres tipos de datos existentes (estructurados, no estructurados y semiestructurados).
Cabe mencionar la importancia que está adquiriendo Spark como evolución de Hadoop.
Evolución temporal de herramientas big data
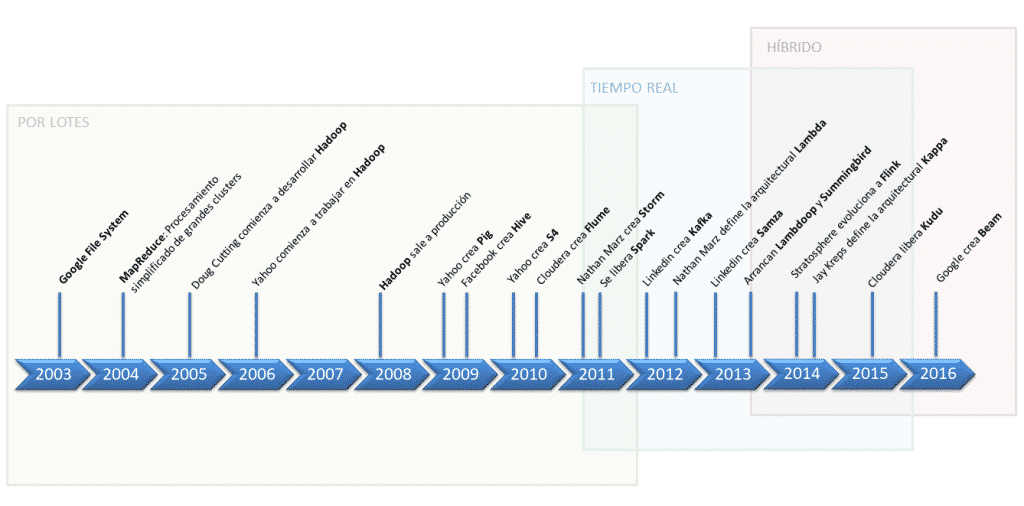
linea temporal big data
Procesamiento big data
El procesamiento de grandes volúmenes de datos se divide en varias fases, a continuación se muestran cada una de ellas así como las herramientas más importantes para cada una de ellas:
Ingesta
Transformación
Procesamiento
- Map-reduce, Storm, Samza, IBM InfoSphere, S4, Tez, Spark Streaming, Flink, …
Almacenamiento
- HDFS,HBase, S3, Kudo, ElasticSearch, Casandra, MongoDB, MariaDB, …
Visualización
- Jupyter, Zeppelin, Google Chart, D3.js, Plotty, Kibana, Shiny, Grabana, Loggy, Splunk, Tableau, QLink, Google Cloud Platform, Power Bi, …
Plataformas de gestión de big data
Plataformas comerciales
- Cloudera
- Hortonworks
- MapR
- Pivotal
Plataformas comerciales en la nube
- Amazon Web Service
- Microsoft Azure
- Google Cloud Platform
- IBM InfoSphere




Trabajo como gestor de clientes en investigación de mercados. Me gustaría tener un encuentro contigo para una posible colaboración en algún proyecto de bigdata. Móvil: 612479393
Estaré en tu conferencia mañana.