Kafka definition
Apache Kafka is a message intermediation system based on the publisher/subscriber model.
Kafka is considered a persistent, scalable, replicated, and fault-tolerant system. To these features is added the speed of readings and writes that make it an excellent tool for real-time communications (streaming).
Apache Kafka provides a multitude of connectors that make it connect to almost any data source, such as connectors for ActiveMQ, IBM MQ, JDBC, JMS, Replicator,…
This message intermediation system also provides many connectors that make you store data anywhere, such as connectors for HDFS, Amazon S3, Elasticsearch, JDBC,…
Features
- Developed in Scala.
- It has connectors for integration with JMS, file system, Hadoop (HDFS), HBase, FTP, JDBC, MongoDB, Assandra, API REST,…
- Allows the implementation of producers/consumers in different languages: Java, Scala, Python, Ruby, C++,…
- It uses an agnostic protocol that goes over HTTP.
- Kafka uses Apache Zookeeper to store the status of the nodes, which maintains a set of partitions of each topic.
- It allows to ingest large volumes of data, enthrones to 100k events/sec.
- Good performance in low latency.
- allows for horizontal scaling.
- Different groups of consumers can consume messages at different rates.
- It acts as a buffer between producers and consumers, ideal for absorbing load peaks.
- Open source Software that is distributed under license Apache 2.0
Architecture
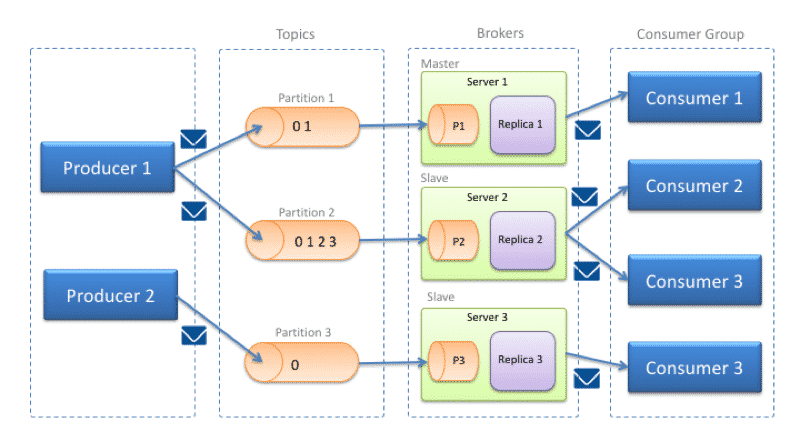
Kafka architecture
Topic: Categories in which to classify the messages sent to Kafka.
Producer (producers) connected clients responsible for posting the messages. These messages are published on one or more topics.
Consumer connected clients subscribed to one or more topics responsible for consuming the messages.
Broker (nodes): Nodes that form the cluster.




0 Comments