Definición de Spark
 Apache Spark es un sistema de computación distribuida de software libre, que permite procesar grandes conjuntos de datos sobre un conjunto de máquinas de forma simultánea, proporcionando escalabilidad horizontal y la tolerancia a fallos.
Apache Spark es un sistema de computación distribuida de software libre, que permite procesar grandes conjuntos de datos sobre un conjunto de máquinas de forma simultánea, proporcionando escalabilidad horizontal y la tolerancia a fallos.
Para cumplir con estas características proporciona un modelo de desarrollo de programas que permite ejecutar código de forma distribuida de tal manera que cada máquina se ocupe de realizar una parte de la tarea y entre todos realicen la tarea global.
Utiliza estructuras de datos RDD (Resilient Data Distributed) que son conjunto de datos de solo lectura, que están distribuidos a lo largo del clúster, mantenidos de manera tolerante a fallos. La disponibilidad de RDDs facilita la implementación de algoritmos iterativos que accedan varias veces a los mismos datos y para el análisis exploratorio de datos.
Para su correcto funcionamiento Spark necesita:
- Gestión de recursos, soporta Standalone, YARN o Apache Mesos.
- Sistema de ficheros distribuido, soporta HDFS, Cassandra o Kudu.
Características
- Velocidad: 100 veces más rápido que Hadoop para ejecuciones en la memoria y 10 veces más rápido cuando se ejecuta en el disco. Esto se debe a reduce el número de operaciones de lectura y escritura de disco. Almacena los datos de procesamiento intermedio en la memoria.
- Soporta múltiples lenguajes de programación: Java, Scala, o Python.
- Compatibilidad: Compatible con Map/Reduce, consultas SQL, flujo de datos, máquina de aprendizaje y algoritmos de grafos.
Componentes
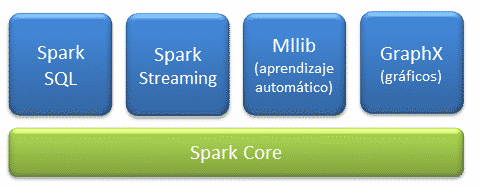
- Core: es en núcleo donde se apoya toda la arquitectura, proporciona:
- Spark SQL: introduce un concepto de abstracción de datos llamado SchemaRD, que proporciona soporte para datos estructurados y semi-estructurados.
- Spark Streaming: es la capa encargada del análisis de datos en tiempo real.
- MLlib: es la capa de aprendizaje automático distribuido sobre el core, que proporciona el famework de aprendizaje automático donde se pueden encontrar multitud de algoritmos de clasificación, regresión, análisis cluster, reducción de dimensionalidad y estadísticos descriptivos.
- GraphX: es la capa de procesamiento gráfico distribuido sobre el core. Al basarse en RDDs inmutables, los gráficos no permiten actualizarse.
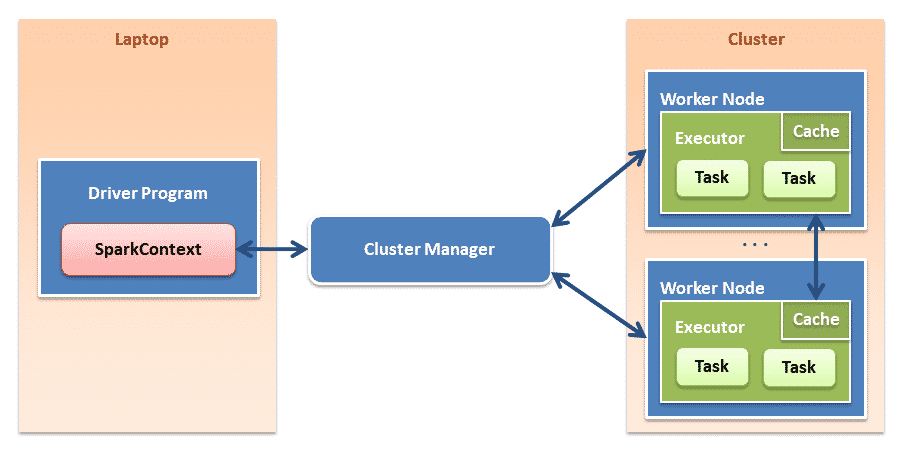
Arquitectura
Tutorial de programación de Spark en Python
- Instalación
- Carga y lectura de ficheros
- RDD
- Procesamiento por lotes (batch)
- Procesamiento en tiempo real (streaming)
- Tuberías (Pipelines)
- Machine learning
- Ejecución distribuida en Spark
Nota: Trucos para optimización de Spark
Fuente: Web Oficial




Diego muy interesante este sitio, gracias por compartir esta información.
Saludos y éxitos!