Spark definition
 Apache Spark is a distributed computing system of free software, which allows to process large sets of data on a set of machines simultaneously, providing horizontal scalability and fault tolerance.
Apache Spark is a distributed computing system of free software, which allows to process large sets of data on a set of machines simultaneously, providing horizontal scalability and fault tolerance.
To meet these features provides a program development model that allows you to run code in a distributed way so that each machine takes care of doing a part of the task and between all of them perform the global task.
It uses RDD (Resilient data distributed) data structures that are set of read-only data, which are scattered throughout the cluster, maintained in a fault-tolerant manner. The availability of RDDs facilitates the implementation of iterative algorithms that access several times the same data and for the exploratory analysis of data.
For proper operation Spark needs:
- Resource management, supports Standalone, YARN or Apache mesos.
- Distributed file system, supports HDFS, Cassandra or Kudu.
Features
- Speed: 100 times faster than Hadoop for executions in memory and 10 times faster when running on disk. This is because it reduces the number of disk read and write operations. Stores the intermediate processing data in memory.
- Supports multiple programming languages: Java, Scala, or Python.
- Compatibility: Supports MAP/Reduce, SQL queries, data flow, learning machine and graph algorithms.
Components
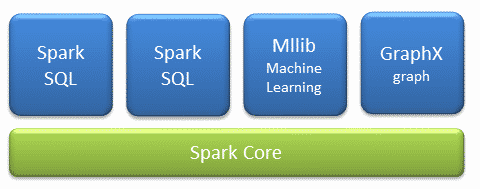
Spark components
- Core: It is in core where all the architecture is supported, it provides:
- Spark SQL: Introduces a concept of data abstraction called SchemaRD, which provides support for structured and semi-structured data.
- Spark streaming: Is the layer in charge of data analysis in real time.
- MLlib: Is the automatic learning layer distributed on the core, which provides the famework of automatic learning where you can find multitude of algorithms of classification, regression, cluster analysis, reduction of dimensionality and statistics Descriptive.
- GraphX: Is the graphical processing layer distributed over the core. Based on immutable RDDs, graphics do not allow updating.
Architecture
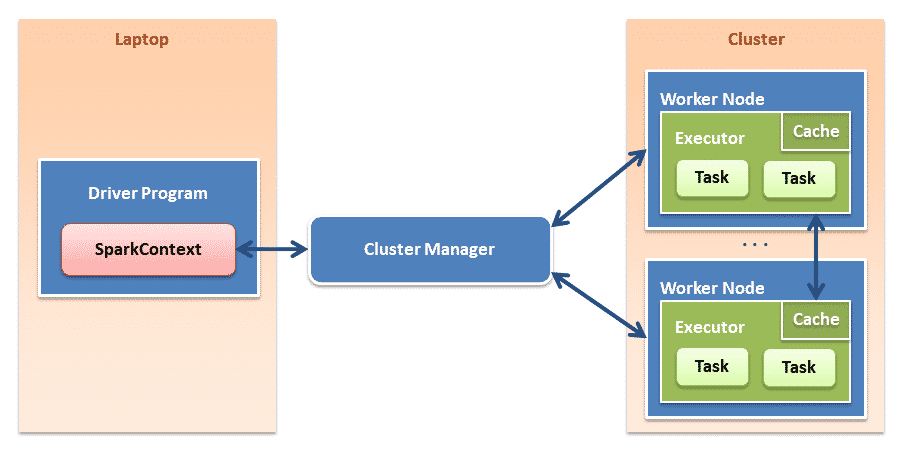
Source: Official website




0 Comments