Hadoop definition
 Apache Hadoop is a distributed system that allows to carry out processing of large volumes of data through cluster, easy to scale.
Apache Hadoop is a distributed system that allows to carry out processing of large volumes of data through cluster, easy to scale.
Broadly speaking, it can be said that Hadoop is composed by two parts:
- Data storage of different types (HDFS)
- Performs data processing tasks in a distributed way (MapReduce).
Hadoop is based on a master-slave architecture.
- The master in HDFS are known as NameNode and are responsible for knowing how the data stored by the cluster.
- Slaves in HDFS are known as DataNodes and are responsible for physically storing data in the cluster.
Architecture
Basic architecture
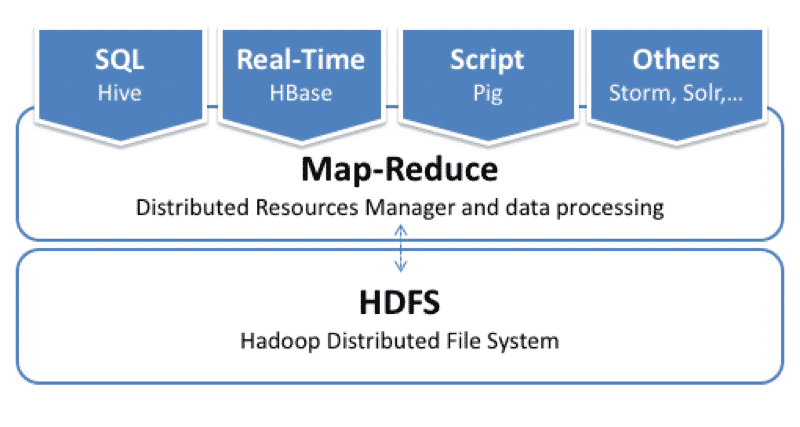
Hadoop basic architecture
Data access: Hive, HBase, Pig, Storm, SOLR,…
MAP-Reduce (programming infrastructure that provides algorithms for performing distributed calculations).
HDFS: Hadoop Distributed File System.
Architecture Evolution with YARN
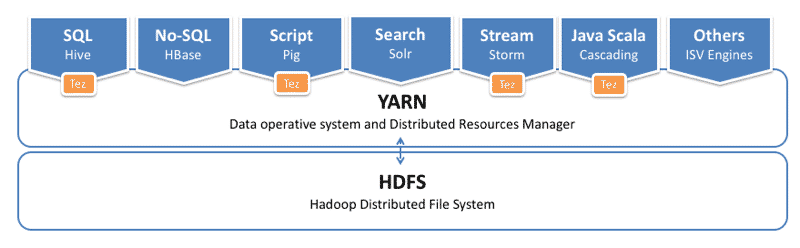
Hadoop YARN achitecture
Apache Hadoop Ecosystem Tools
Data ingestion
- Apache KAFKA: Intermediation message system based on the publisher/subscriber model.
- Apache Flume: System of ingesting semi-structured or unstructured data in streaming on HDFS or Hbase.
- Apache Nifi: is an ETL tool that is responsible for loading data from different sources, passes through a process flow for treatment, and dumps them in another source
Data processing
- Apache Hadoop Map-Reduce: Provides batch data processing.
- Apache Storm — provides batch data processing.
- Apache Samza: Provides real-time data processing.
- Apache Tez: Provides real-time data processing.
- Apache Spark Streaming: provides hybrid data processing.
- Apache Flink: provides hybrid data processing.
Data transformation
- Apache Hive: Converts SQL or PIG statements into a MapReduce job.
- Apache Hue: Provides a graphical browser interface to perform your Hive work in a simple way.
- Apache Impala: Alternative to Hive used by Cloudera. SQL query engine for massive parallel processing (MPP) of data stored in a Hadoop cluster.
- Apache Sqoop: Provides bidirectional data transfer between Hadoop and an SQL databases (structured data)
- Apache Pig: High-level language for MapReduce coding. It converts a high-level description of how data should be processed into MapReduce’s “jobs,” without having to write long jobs chains each time, improving the productivity of developers.
- Apache Nifi: is an ETL tool that is responsible for loading data from different sources, passes through a process flow for treatment, and dumps them in another source.
Storage
- HDFS: Hadoop Distributed File System.
- Apache Hbase: Column-oriented database management system.
- Apache Kudo: Column-oriented storage database manager for Cloudy.
Reporting data
- Apache Zeppelin: For fast data visualization. Similar to Jupiter notebook.
Security
- Apache Ranger: Framework to enable, monitor and manage comprehensive data security across Hadoop Platform.
- Apache Sentry: A system for applying the role-based authorization of fine granularity to data and metadata stored in a Hadoop Cluster.
- Knox: Application Gateway to interact with the REST API and Apache Hadoop UI.
Machine Learning
- Apache Mahout: Framework of distributed linear algebra and mathematically expressive Scala DSL, designed quickly implement algorithms.
- Spark MLlib: Machine learning Library, which contains the original API built on the RDD.
- SparkML: Machine learning Library, which provides a top-level API built on DataFrames.
- FlinkML: Machine learning library for Flink.
Data labelling
- Apache Falcon
- Apache Atlas




very informative